1.Представление данных с помощью модели "сущность-связь".
Удобным инструментом представления данных является модель "сущность-связь". Из модели "сущность-связь" могут быть порождены все существующие модели данных (иерархическая, сетевая, реляционная, объектная), поэтому она является наиболее общей. Основными составляющими этой модели являются: типы сущностей, атрибуты, типы связей. Типы сущностей – объект или концепция, которая характеризуется на данном предприятии и имеет независимое существование. Типы сущностей бывают реальными (сотрудник, станок) и абстрактными (сущность расписания)
Сущность - это объект, который может быть идентифицирован неким способом, отличающим его от других объектов. Примеры: конкретный человек, предприятие, событие и т.д. Набор сущностей - множество сущностей одного типа (обладающих одинаковыми свойствами). Сущность фактически представляет из себя множество атрибутов, которые описывают свойства всех членов данного набора сущностей. Каждая сущность определяется именем и списком свойств. Связь - это ассоциация, установленная между несколькими сущностями. Ключ сущности - это один или более атрибутов уникально определяющих данную сущность. Роль сущности в связи - функция, которую выполняет сущность в данной связи. Набор связей - это отношение между n сущностями, каждая из которых относится к некоторому набору сущностей.
Число сущностей может быть ассоциировано через набор связей с другой сущностью. Их называют степенью связи. Рассмотрение степеней особенно полезно для бинарных связей. Могут существовать следующие степени бинарных связей:
один к одному (обозначается 1 : 1 ). Это означает, что в такой связи сущности с одной ролью всегда соответствует не более одной сущности с другой ролью.
один ко многим ( 1 : n ). В данном случае сущности с одной ролью может соответствовать любое число сущностей с другой ролью.
много к одному (n : 1 ). Эта связь аналогична отображению 1 : n.
многие ко многим ( n : n ). В этом случае каждая из ассоциированных сущностей может быть представлена любым количеством экземпляров.
Если существование сущности x зависит от существования сущности y, то x называется зависимой сущностью (иногда сущность x называют "слабой", а "сущность" y - сильной).
Прямоугольники обозначают сущности, а ромб - связь.

2.Диаграмма "сущность-связь".
Важным свойством модели "сущность-связь" является то, что она может быть представлена в виде графической схемы. Здесь мы будем использовать обозначение сущностей, связей, атрибутов, степеней и кардинальностей связей. В таблице приводится список используемых здесь обозначений.
![]() Набор независимых
сущностей
Набор независимых
сущностей
![]() Набор зависимых
сущностей
Набор зависимых
сущностей
![]() Атрибут
Атрибут
![]() Ключевой атрибут
Ключевой атрибут
![]() Набор связей
Набор связей
Атрибуты с сущностями и сущности со связями соединяются прямыми линиями. При этом для указания кардинальностей связей используются обозначения, введенные в предыдущем параграфе.
В процессе построения диаграммы можно выделить несколько очевидных этапов:
1. Идентификация представляющих интерес сущностей и связей.
2. Идентификация семантической информации в наборах связей (например, является ли некоторый набор связей отображением 1:n).
3. Определение кардинальностей связей.
4. Определение атрибутов и наборов их значений (доменов).
5. Организация данных в виде отношений "сущность-связь".
Прямоугольники обозначают сущности, а ромб - связь.

3.Целостность данных.
Модель "сущность-связь" также полезна для понимания и спецификации ограничений, направленных на поддержание целостности данных. В модели имеется три типа ограничений на значения:
1. ограничения на допустимые значения в наборе значений (домене). Домен можно трактовать как область определения атрибута, которая может быть задана либо непрерывным или дискретным интервалом, либо фиксированным списком значений.
2. ограничения на разрешенные значения для каждого атрибута. Например, возраст сотрудников может быть ограничен интервалом от 18 до 65 лет.
3. ограничения на существующие значения в базе данных. Например, сумма отчислений с зарплаты сотрудника не должна превышать самой зарплаты.
Ограничения целостности:
1. Целостность сущностей.
Ни один атрибут первичного ключа не может содержать неопределенных значений обозначенных определителем NULL. (NULL указывает на то, что в данный момент значение атрибута неизвестно или неприемлемо для данного домена.
2. Ссылочная целостность.
Если в отношении существует внешний ключ, то значение внешнего ключа должно соответствовать значению потенциального ключа, либо задаваться определителем NULL.
3. Корпоративное ограничение целостности.
Дополнительные правила поддержки целостности данных, определяемые пользователем или администратором.
4.Реляционная модель данных
Реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления, т.е. представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений. Три цели создания реляционной модели:
- обеспечение высокой степени независимости от данных. Прикладные программы не должны зависеть от изменений внутреннего представления данных, в частности от изменений организации файлов, переупорядочивания записей и путей доступа.
- создание фундамента для запросов, построенных на выводах и взглядах на информацию
- устранение проблем непротиворечивости и избыточности данных.
Основана реляционная модель на математическом понятии – отношение, физическим представлением которого является таблица. Отношение – плоская таблица, состоящая из столбцов и строк.
В любой реляционной СУБД предполагается, что пользователь воспринимает базу данных как набор таблиц. Атрибут – поименованный столбец отношения. Они используются для хранения информации об объектах. В реляционной модели отношения используются для хранения информации об объектах, представленных в базе данных. Отношение обычно имеет вид двумерной таблицы, в которой строки соответствуют отдельным записям, а столбцы — атрибутам. При этом атрибуты могут располагаться в любом порядке — независимо от их переупорядочивания отношение будет оставаться одним и тем же, а потому иметь тот же смысл. Домен – набор допустимых значений одного или нескольких атрибутов. Кортеж – строка отношения.
Степень отношения – количество атрибутов или количество столбцов в таблице.
Кардинальность отношений – количество кортежей, или записей, или строк.
Количество содержащихся в отношении кортежей называется кардинальностью
отношения. И, наконец, мы подошли к определению самой реляционной базы данных – это набор нормализованных отношений.
Терминология, используемая в реляционной модели, порой может привести к путанице, поскольку помимо предложенных двух наборов терминов существует еще один — третий. Отношение в нем называется файлом (file), кортежи — записями (records), а атрибуты — полями (fields). Эта терминология основана на том факте, что физически реляционная СУБД может хранить каждое отношение в отдельном файле.
6.Операции над данными (реляционная алгебра).
Эти операции связаны с изменением состава кортежей в каком-либо отношении.
ДОБАВИТЬ - необходимо задать имя отношения и ключ кортежа. УДАЛИТЬ - необходимо указать имя отношения, а также идентифицировать кортеж или группу кортежей, подлежащих удалению. ИЗМЕНИТЬ - выполняется для названного отношения и может корректировать как один, так и несколько кортежей. Операции обработки отношений. На входе каждой такой операции используется одно или несколько отношений, результатом выполнения операции всегда является новое отношение. В реляционной алгебре определены следующие операций обработки отношений: Проекция (Вертикальное Подмножество), операция проекции представляет из себя выборку из каждого кортежа отношения значений атрибутов, входящих в список A, и удаление из полученного отношения повторяющихся строк. Выборка (Ограничение, Горизонтальное Подмножество), на входе используется одно отношение, результат - новое отношение, построенное по той же схеме, содержащее подмножество кортежей исходного отношения, удовлетворяющих условию выборки.
Объединение, отношения-операнды в этом случае должны быть определены по одной схеме. Результирующее отношение содержит все строки операндов за исключением повторяющихся.
Пересечение, на входе операции два отношения, определенные по одной схеме. На выходе - отношение, содержащие кортежи, которые присутствуют в обоих исходных отношениях.
Разность, операция во многом похожая на Пересечение, за исключением того, что в результирующем отношении содержатся кортежи, присутствующие в первом и отсутствующие во втором исходных отношениях. Декартово Произведение, входные отношения могут быть определены по разным схемам. Схема результирующего отношения включает все атрибуты исходных. Кроме того: степень результирующего отношения равна сумме степеней исходных отношений мощность результирующего отношения равна произведению мощностей исходных Отношений. Соединение, данная операция имеет сходство с Декартовым Произведением. Однако, здесь добавлено условие, согласно которому вместо полного произведения всех строк в результирующее отношение включаются только строки, удовлетворяющие опредленному соотношению между атрибутами соединения (А1,A2) соответствующих отношений.
Деление, пусть отношение R , называемое делимым, содержит атрибуты (A1,A2,...,An). Отношение S - делитель содержит подмножество атрибутов A: (A1,A2,...,Ak) (k<n). Результирующее отношение C определено на атрибутах отношения R, которых нет в S, т.е. Ak+1,Ak+2,...,An. Кортежи включаются в результирующее отношение C только в том случае, если его декартово произведение с отношением S содержится в делимом R.
7.Проекция (Вертикальное Подмножество).
Операция проекции представляет из себя выборку из каждого кортежа отношения значений атрибутов, входящих в список A, и удаление из полученного отношения повторяющихся строк.

8.Выборка (Ограничение, Горизонтальное Подмножество).
На входе используется одно отношение, результат - новое отношение, построенное по той же схеме, содержащее подмножество кортежей исходного отношения, удовлетворяющих условию выборки.

9. Разность. Операция во многом похожая на ПЕРЕСЕЧЕНИЕ, за исключением того, что в результирующем отношении содержатся кортежи, присутствующие в первом и отсутствующие во втором исходных отношениях.
11.Объединение.
Отношения-операнды в этом случае должны быть определены по одной схеме. Результирующее отношение содержит все строки операндов за исключением повторяющихся.

13.Функциональные зависимости.
Реляционная база данных содержит как структурную, так и семантическую информацию. Структура базы данных определяется числом и видом включенных в нее отношений, и связями типа "один ко многим", существующими между кортежами этих отношений. Семантическая часть описывает множество функциональных зависимостей, существующих между атрибутами этих отношений. Дадим определение функциональной зависимости.
Если даны два атрибута X и Y некоторого отношения, то говорят, что Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y.
Функциональная зависимость обозначается X -> Y. Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения.
Можно сказать, что функциональные зависимости представляют собой связи типа "один ко многим", существующие внутри отношения.
Избыточная функциональная зависимость - зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Корректной считается такая схема базы данных, в которой отсутствуют избыточные функциональные зависимости. В противном случае приходится прибегать к процедуре декомпозиции (разложения) имеющегося множества отношений. При этом порождаемое множество содержит большее число отношений, которые являются проекциями отношений исходного множества. (Операция проекции описана в разделе, посвященном реляционной алгебре). Обратимый пошаговый процесс замены данной совокупности отношений другой схемой с устранением избыточных функциональных зависимостей называется нормализацией.
Условие обратимости требует, чтобы декомпозиция сохраняла эквивалентность схем при замене одной схемы на другую, т.е. в результирующих отношениях:
§ не должны появляться ранее отсутствовавшие кортежи;
на отношениях новой схемы должно выполняться исходное множество функциональных зависимостей.
14.1NF - первая нормальная форма.
Простой атрибут - атрибут, значения которого атомарны (неделимы). Сложный атрибут - получается соединением нескольких атомарных атрибутов, которые могут быть определены на одном или разных доменах. (его также называют вектор или агрегат данных). Определение первой нормальной формы: отношение находится в 1NF если значения всех его атрибутов атомарны. Пример: В базе данных отдела кадров предприятия необходимо хранить сведения о служащих, которые можно попытаться представить в отношении
Служащий (таб_№, имя, дата_рождения, история_работы, дети). Атрибуты "история_работы" и "дети" являются сложными, и атрибут "история_работы" включает еще один сложный атрибут "история_зарплаты". Данные агрегаты выглядят следующим образом: история_работы (дата_приема, название, история_зарплаты), история_зарплаты (дата_назначения, зарплата), дети (имя, год_рождения).
Их связь представлена на рис.

Для приведения исходного отношения
СЛУЖАЩИЙ к первой нормальной форме необходимо декомпозировать его на четыре
отношения, так как это показано на следующем рисунке:

Нормализованное множество отношений.
Напомним, что именно внешние ключи служат для представления функциональных зависимостей, существующих в исходном отношении. Эти функциональные зависимости обозначены линиями со стрелками.
Алгоритм нормализации описан Е.Ф.Коддом следующим образом: Начиная с отношения, находящегося на верху дерева, берется его первичный ключ, и каждое непосредственно подчиненное отношение расширяется путем вставки домена или комбинации доменов этого первичного ключа. Первичный Ключ каждого расширенного таким образом отношения состоит из Первичного Ключа, который был у этого отношения до расширения и добавленного Первичного Ключа родительского отношения.
После этого из родительского отношения вычеркиваются все непростые домены, удаляется верхний узел дерева, и эта же процедура повторяется для каждого из оставшихся поддеревьев.
16.3NF - третья нормальная форма.
Определение транзитивной функциональной зависимости.:
Пусть X, Y, Z - три атрибута некоторого отношения. При этом X --> Y и Y
--> Z, но обратное
соответствие отсутствует, т.е. Z -/-> Y и Y -/-> X. Тогда Z
транзитивно зависит от X.
Пусть имеется отношение ХРАНЕНИЕ (ФИРМА, СКЛАД, ОБЪЕМ), которое содержит
информацию о фирмах, получающих товары со складов, и объемах этих складов.
Ключевой атрибут - "фирма". Если каждая фирма может получать товар
только с одного склада, то в данном отношении имеются следующие функциональные
зависимости:
§ фирма -> склад
§ склад -> объем
При этом возникают аномалии:
§ если в данный момент ни одна фирма не получает товар со склада, то в базу данных нельзя ввести данные о его объеме (т.к. не определен ключевой атрибут)
§ если объем склада изменяется, необходим просмотр всего отношения и изменение кортежей для всех фирм, связанных с данным складом.
Для устранения этих аномалий необходимо декомпозировать исходное отношение на два:
§ ХРАНЕНИЕ (ФИРМА, СКЛАД)
§ ОБЪЕМ_СКЛАДА (СКЛАД, ОБЪЕМ)
Определение третьей нормальной формы: Отношение находится в 3НФ, если оно находится во 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
18.Многозначные зависимости и четвертая нормальная форма (4NF).
Четвертая нормальная форма касается отношений, в которых имеются повторяющиеся наборы данных. Декомпозиция, основанная на функциональных зависимостях, не приводит к исключению такой избыточности. В этом случае используют декомпозицию, основанную на многозначных зависимостях.
Многозначная зависимость является обобщением функциональной зависимости и рассматривает соответствия между множествами значений атрибутов.
Пример в приложении 1
Это отношение имеет значительную избыточность и его использование приводит к возникновению аномалии обновления. Например, добавление информации о том, что профессор K будет также читать лекции по курсу "Теория упругости" приводит к необходимости добавить два кортежа (по одному для каждого написанного им учебника) вместо одного. Тем не менее, отношение ПРЕПОДАВАТЕЛЬ находится в NFBC (ключевой атрибут - ИМЯ).
Заметим, что указанные аномалии исчезают при замене отношения ПРЕПОДАВАТЕЛЬ его проекциями:
Аномалия обновления возникает в данном случае потому, что в отношении ПРЕПОДАВАТЕЛЬ имеются:
1. зависимость множества значений атрибута КУРС от множества значений атрибута ИМЯ
2. зависимость множества значений атрибута УЧЕБНОЕ_ПОСОБИЕ от множества значений атрибута ИМЯ.
Такие зависимости и называются многозначными и обозначаются как
ИМЯ ->> КУРС ИМЯ ->> УЧЕБНОЕ_ПОСОБИЕ
Нетрудно показать, что многозначные зависимости всегда образуют связанные пары, поэтому их часто обозначают
ИМЯ ->> КУРС | УЧЕБНОЕ_ПОСОБИЕ
Очевидно, что каждая функциональная зависимость является многозначной, но не каждая многозначная зависимость является функциональной.
Определение четвертой нормальной формы: Отношение находится в 4NF если оно находится в BCNF и в нем отстутсвуют многозначные зависимости, не являющиеся функциональными зависимостями.
19.Целостность сущностей.
Объект реального мира представляется в реляционной базе данных как кортеж некоторого отношения. Требование целостности сущностей заключается в следующем: каждый кортеж любого отношения должен отличатся от любого другого кортежа этого отношения (т.е. любое отношение должно обладать первичным ключом).
Вполне очевидно, что если данное требование не соблюдается (т.е. кортежи в рамках одного отношения не уникальны), то в базе данных может хранится противоречивая информация об одном и том же объекте. Поддержание целостности сущностей обеспечивается средствами системы управления базой данных (СУБД). Это осуществляется с помощью двух ограничений:
§ при добавлении записей в таблицу проверяется уникальность их первичных ключей
не позволяется изменение значений атрибутов, входящих в первичный ключ.
21.Типы данных SQL.
Символьные типы данных - содержат буквы, цифры и специальные символы.
CHAR или CHAR(n) -символьные строки фиксированной длины. Длина строки определяется параметром n. CHAR без параметра соответсвует CHAR(1). Для хранения таких данных всегда отводится n байт вне зависимости от реальной длины строки. VARCHAR(n) - символьная строка переменной длины. Для хранения данных этого типа отводится число байт, соответствующее реальной длине строки.
Целые типы данных - поддерживают только целые числа (дробные части и десятичные точки не допускаются). Над этими типами разрешается выполнять арифметические операции и применять к ним агрегирующие функции (определение максимального, минимального, среднего и суммарного значения столбца реляционной таблицы). INTEGER или INT- целое, для хранения которого отводится, как правило, 4 байта. (Замечание: число байт, отводимое для хранения того или иного числового типа данных зависит от используемой СУБД и аппаратной платформы, здесь приводятся наиболее "типичные" значения) Интервал значений от - 2147483647 до + 2147483648 Вещественные типы данных - описывают числа с дробной частью. FLOAT и SMALLFLOAT - числа с плавающей точкой (для хранения отводится обычно 8 и 4 байта соответсвенно). DECIMAL(p) - тип данных аналогичный FLOAT с числом значащих цифр p. DECIMAL(p,n) - аналогично предыдущему, p - общее количество десятичных цифр, n - количество цифр после десятичной запятой. Денежные типы данных - описывают, естественно, денежные величины. Если в ваша система такого типа данных не поддерживает, то используйте DECIMAL(p,n). Дата и время - используются для хранения даты, времени и их комбинаций. Большинство СУБД умеет определять интервал между двумя датами, а также уменьшать или увеличивать дату на определенное количество времени. DATE - тип данных для хранения даты. TIME - тип данных для хранения времени. INTERVAL - тип данных для хранения верменного интервала. DATETIME Двоичные типы данных - позволяют хранить данные любого объема в двоичном коде. Определения этих типов наиболее сильно различаются от системы к системе, часто используются ключевые слова: BINARY BYTE BLOB Последовательные типы данных - используются для представления возрастающих числовых последовательностей. SERIAL - тип данных на основе INTEGER, позволяющий сформировать уникальное значение.
NULL - "не определено". Это значение имеет каждый элемент столбца до тех пор, пока в него не будут введены данные. При создании таблицы можно явно указать СУБД могут ли элементы того или иного столбца иметь значения NULL (это не допустимо, например, для столбца, являющего первичным ключом).
22.Операторы создания схемы базы данных.
При описании команд предполагается, что:
· текст, набранный строчными буквами является обязательным
· текст, набранный прописными буквами и заключенный в угловые скобки (например, <имя_базы_данных>)обозначает переменную, вводимую пользователем
· в квадратные скобки (например, [NOT NULL]) заключается необязательная часть команды
· взаимоисключающие элементы команды разделяются вертикальной чертой (например, [UNIQUE | PRIMARY KEY]).
Оператор создания БД: Create Database <имя_базы_данных>
Оператор удаления БД: Drop Database <имя_базы_данных>
Оператор создания таблицы: Create Table <имя_таблицы>
(<имя_столбца><тип_столбца>
[NOT NULL]
[UNIQUE | PRIMARY KEY], …)
Оператор удаления таблицы: Drop Table <имя_таблицы>
· NOT NULL - в этом случае элементы столбца всегда должны иметь определенное значение (не NULL)
· один из взаимоисключающих параметров UNIQUE - значение каждого элемента столбца должно быть уникальным или PRIMARY KEY - столбец является первичным ключом.
Оператор редактирования или модификации таблиц: добавить столбцы, удалить столбцы, редактировать столбцы
23.Операторы управления правами доступа.
Не каждому пользователю прикладной системы можно разрешить получать информацию из какой-либо таблицы, а тем более изменять в ней данные.
Права пользователя на уровне таблицы определяются следующими ключевыми словами:
·
SELECT -
получение информации из таблицы; UPDATE
- изменение информации в таблице; INSERT
- добавление записей в таблицу ;DELETE
- удаление записей из таблицы; INDEX
- индексирование таблицы; ALTER
- изменение схемы определения таблицы; ALL
- все права
В том случае, когда одинаковые права надо предоставить сразу
всем пользователям, вместо выполнения команды GRANT(управление правами доступа) для каждого из них,
можно вместо имени пользователя указать ключевое слово PUBLIC. Отмена прав осуществляется
командой REVOKE.
24.Команды модификации данных.
К этой группе относятся операторы добавления, изменения и удаления записей.
1. Добавление:
INSERT INTO <имя_таблицы> [ (<имя_столбца>,<имя_столбца>,...) ] VALUES (<значение>,<значение>,..)
2. Модификация записей:
UPDATE <имя_таблицы> SET <имя_столбца>=<значение>,...
[WHERE <условие>]
Если задано ключевое слово WHERE и условие, то команда UPDATE применяется только к тем записям, для которых оно выполняется. Если условие не задано, UPDATE применяется ко всем записям.
3. Удаление записей:
DELETE FROM <имя_таблицы> [ WHERE <условие> ]
Удаляются все записи, удовлетворяющие указанному условию. Если ключевое слово WHERE и условие отсутствуют, из таблицы удаляются все записи.
26.Вычисления внутри SELECT.
SQL позволяет выполнять различные арифметические операции над столбцами результирующего отношения. В конструкции <список_выбора> можно использовать константы, функции и их комбинации с арифметическими операциями и скобками. Например, чтобы узнать сколько лет прошло с 1992 года (год принятия стандарта SQL-92) до публикации той или иной книги можно выполнить команду:
SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992;
В арифметических вражения допускаются операции сложения (+), вычитания (-), деления (/), умножения (*), а также различные функции (COS, SIN, ABS - абсолютное значение и т.д.). Также в запрос можно добавить строковую константу:
SELECT 'the title of the book is', title, yearpub-1992
FROM titles WHERE yearpub > 1992;
В SQL также определены так называемые агрегатные функции, которые совершают действия над совокупностью одинаковых полей в группе записей. Среди них:
AVG(<имя поля>) - среднее по всем значениям данного поля
COUNT(<имя поля>) или COUNT (*) - число записей
MAX(<имя поля>) - максимальное из всех значений данного поля
MIN(<имя поля>) - минимальное из всех значений данного поля
SUM(<имя поля>) - сумма всех значений данного поля
Следует учитывать, что каждая агрегирующая функция возвращает единственное значение. Примеры: определить дату публикации самой "древней" книги в нашей базе данных
SELECT MIN(yearpub) FROM titles;
подсчитать количество книг в нашей базе данных:
SELECT COUNT(*) FROM titles;
27.Групировка данных.
Группировка данных в операторе SELECT осуществляется с помощью ключевого слова GROUP BY и ключевого слова HAVING, с помощью которого задаются условия разбиения записей на группы.
GROUP BY неразрывно связано с агрегирующими функциями, без них оно практически не используется. GROUP BY разделяет таблицу на группы, а агрегирующая функция вычисляет для каждой из них итоговое значение.
Слово HAVING работает следующим образом: сначала GROUP BY разбивает строки на группы, затем на полученные наборы накладываются условия HAVING.
Другой вариант использования HAVING - включить в результат только те издательтва, название которых оканчивается на подстроку "Press":
В чем различие между двумя этими вариантами использования HAVING? Во втором варианте условие отбора записей мы могли поместить в раздел ключевого слова WHERE, в первом же варианте этого сделать не удастся, поскольку WHERE не допускает использования агрегирующих функций.
28.Cортировка данных.
Для сортировки данных, получаемых при помощи оператора SELECT служит ключевое слово ORDER BY. С его помощью можно сортировать результаты по любому столбцу или выражению, указанному в <списке_выбора>. Данные могут быть упорядочены как по возрастанию, так и по убыванию. Пример: сортировать список авторов по алфавиту:
SELECT author FROM authors ORDER BY author;
Более сложный пример: получить список авторов, отсортированный по алфавиту, и список их публикаций, причем для каждого автора список книг сортируется по времени издания в обратном порядке (т.е. сначала более "свежие" книги, затем все более "древние"):
SELECT authors.author,titles.title,titles. yearpub,publishers.publisher
FROM authors,titles,publishers,titleauthors
WHERE titleauthors.au_id=authors.au_id AND
titleauthors.title_id=titles.title_id AND
titles.pub_id=publishers.pub_id
ORDER BY authors.author ASC, titles.yearpub DESC;
Ключевое слово DESC задает здесь обратный порядок сортировки по полю yearpub, ключевое слов ASC (его можно опускать) - прямой порядок сортировки по полю author.
29.Этапы проектирования данных
Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. В теории проектирования информационных систем предметную область (или, если угодно, весь реальный мир в целом) принято рассматривать в виде трех представлений:
1. представление предметной области в том виде, как она реально существует
2. как ее воспринимает человек (имеется в виду проектировщик базы данных)
3. как она может быть описана с помощью символов.
Т.е. говорят, что мы имеем дело с реальностью, описанием (представлением) реальности и с данными, которые отражают это представление.
Данные, используемые для описания предметной области, представляются в виде трехуровневой схемы (так называемая модель ANSI/SPARC):
![]() Внешнее
представление (внешняя схема) данных является совокупностью требований к данным
со стороны некоторой конкретной функции, выполняемой пользователем.
Концептуальная схема является полной совокупностью всех требований к данным,
полученной из пользовательских представлений о реальном мире. Внутренняя схема
- это сама база данных.
Внешнее
представление (внешняя схема) данных является совокупностью требований к данным
со стороны некоторой конкретной функции, выполняемой пользователем.
Концептуальная схема является полной совокупностью всех требований к данным,
полученной из пользовательских представлений о реальном мире. Внутренняя схема
- это сама база данных.
Отсюда вытекают основные этапы, на которые разбивается процесс проектирования базы данных информационной системы:
1.Концептуальное проектирование - сбор, анализ и редактирование требований к данным. Для этого осуществляются следующие мероприятия:
§ обследование предметной области, изучение ее информационной структуры
§ выявление всех фрагментов, каждый из которых харакетризуется пользовательским представлением, информационными объектами и связями между ними, процессами над информационными объектами
§ моделирование и интеграция всех представлений
По окончании данного этапа получаем концептуальную модель, инвариантную к структуре базы данных. Часто она представляется в виде модели "сущность-связь".
2.Логическое проектирование - преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных и спецификации прикладных программ. На этом этапе часто моделируют базы данных применительно к различным СУБД и проводят сравнительный анализ моделей.
Физическое проектирование - определение особенностей хранения данных, методов доступа и т.д.
31.Блокировка
Транзакция - атомарные действия над БД, переводящего ее из одного целостного состояния в другое целостное состояние. Другими словами, транзакция - это последовательность операций, которые должны быть или все выполнены или все не выполнены (все или ничего). Принудительное упорядочение транзакций обеспечивается с помощью механизма блокировок.
Суть этого механизма в следующем: если для выполнения некоторой транзакции необходимо, чтобы некоторый объект базы данных (кортеж, набор кортежей, отношение, набор отношений,..) не изменялся непредсказуемо и без ведома этой транзакции, такой объект блокируется. Основными видами блокировок являются: блокировка со взаимным доступом, называемая также S-блокировкой (от Shared locks) и блокировкой по чтению. монопольная блокировка (без взаимного доступа), называемая также X-блокировкой от (eXclusive locks) или блокировкой по записи. Этот режим используется при операциях изменения, добавления и удаления объектов. При этом: если транзакция налагает на объект X-блокировку, то любой запрос другой транзакции с блокировкой этого объекта будет отвергнут. если транзакция налагает на объект S-блокировку, то запрос со стороны другой транзакции с X-блокировокй на этот объект будет отвергнут ; запрос со стороны другой транзакции с S-блокировокй этого объекта будет принят
Транзакция, запросившая доступ к объекту, уже захваченному другой транзакцией в несовместимом режиме, останавливается до тех пор, пока захват этого объекта не будет снят.
Доказано, что сериализуемость транзакций (или, иначе, их изоляция) обеспечивается при использовании двухфазного протокола блокировок (2LP - Two-Phase Locks), согласно которому все блокировки, произведенные транзакцией, снимаются только при ее завершении. Т.е выполение транзакции разбивается на две фазы: (1) - накопление блокировок, (2) - освобождение блокировок в результате фиксации или отката.
К сожалению, применение механизма блокировки приводит к замедлению обработки транзакций, поскольку система вынуждена ожидать пока освободятся данные, захваченные конкурирующей транзакцией. Решить эту проблему можно за счет уменьшения фрагментов данных, захватываемых транзакцией. В зависимости от захватываемых объектов различают несколько уровней блокировки: блокируется вся база данных - очевидно, этот вариант неприемлим, поскольку сводит многопользовательский режим работы к однопользовательскому; блокируются отдельные таблицы ; блокируются страницы (страница - фрагмент таблицы размером обычно 2-4 Кб, единица выделения памяти для обработки данных системой) ; блокируются записи ; блокируются отдельные поля
Современные СУБД, как правило, могут осуществлять блокировку на уровне записей или страниц.
32.Архитектура "клиент-сервер".
Клиент и сервер какого-либо ресурса могут находится, как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
§ ввод и отображение данных (взаимодействие с пользователем);
§ прикладные функции, характерные для данной предметной области;
§ функции управления ресурсами (файловой системой, базой даных и т.д.)
Поэтому, в любом приложении выделяются следующие компоненты:
§ компонент представления данных
§ прикладной компонент
§ компонент управления ресурсом
Связь между компонентами осуществляется по определенным правилам, которые называют "протокол взаимодействия".
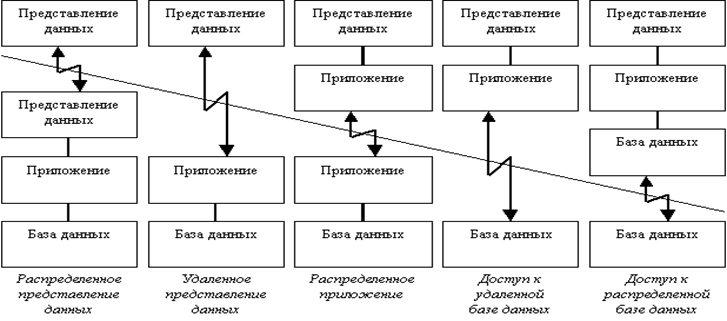 Модели взаимодействия клиент-сервер.
Модели взаимодействия клиент-сервер.
Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия клиент-сервер (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя узлами):
На практике сейчас обычно используются смешанный подход:
- простейшие прикладные функции выполняются хранимыми процедурами на сервере
- более сложные реализуются на клиенте непосредственно в прикладной программе
В последнее время также наблюдается тенденция ко все большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две и более частей, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате.
В этом случае двухзвенная архитектура клиент-сервер становится трехзвенной, а к некоторых случаях, она может включать и больше звеньев.
