2.1. Трехуровневая архитектура ANSI-SPARC
Первая попытка создания стандартной терминологии и общей архитектуры СУБД была предпринята в 1971 году группой, называемой DBTG. Она была создана после конференции CODASYL (Conference on Data Systems and Languaguages — Конференция по языкам и системам данных), прошедшей в этом же году. Группа DBTG признала необходимость использования двухуровневого подхода, построенного на основе использования системного представления, т.е. схемы (schema), и пользовательских представлений, т.е. подсхем (subschema). Сходные терминология и архитектура были предложены в 1975 году Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального Института Стандартизации США (American National Standard Institute— ANSI), ANSI/X3/SPARC (ANSI, 1975). Комитет ANSI/SPARC признал необходимость использования трехуровневого подхода. В этих материалах отражены предложения, которые были сделаны организациями Guide/Share, состоящими из пользователей продуктов корпорации IBM, и опубликованы за несколько лет до этого. Основное внимание в них было сконцентрировано на необходимости воплощения независимого уровня для изоляции программ от особенностей представления данных на более низком уровне (Guide/Share, 1970). Хотя модель ANSI/SPARC не стала стандартом, тем не менее она все еще представляет собой основу для понимания некоторых функциональных особенностей СУБД.
В данном случае для нас наиболее фундаментальным моментом в этих и последующих отчетах исследовательских групп является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных. Эти уровни формируют трехуровневую архитектуру, которая охватывает внешний, концептуальный и внутренний уровни, как показано на рис. 2.1. Цель трехуровневой архитектуры заключается в отделении пользовательского представления базы данных от ее физического представления. Ниже перечислено несколько причин, по которым желательно выполнять такое разделение.
• Каждый пользователь
должен иметь возможность обращаться к одним и
тем же
данным, используя свое собственное представление о них. Каж
дый
пользователь должен иметь возможность изменять свое представле
ние о
данных, причем это изменение не должно оказывать влияния на
других
пользователей.
• Пользователи не должны
непосредственно иметь дело с такими подробно
стями
физического хранения данных в базе, как индексирование и хеши
рование (приложение А,
"Учебный проект Wellmeadows Hospital"). Иначе
говоря, взаимодействие пользователя с базой
не должно зависеть от осо
бенностей хранения в ней данных.
• Администратор базы
данных (АБД) должен иметь возможность изменять
структуру хранения данных в базе, не оказывая влияния на пользователь
ские
представления.
• Внутренняя структура
базы данных не должна зависеть от таких измене
ний
физических аспектов хранения информации, как переключение на но
вое
устройство хранения.
•
АБД
должен иметь возможность изменять концептуальную или гло
бальную
структуру базы данных без какого-либо влияния на всех поль
зователей.
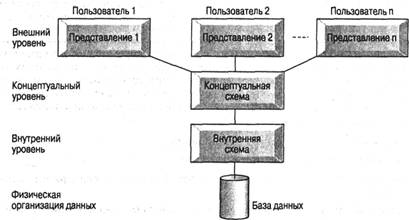 |
Рис. 2.1. Трехуровневая архитектура ANSI-SPARC
Уровень, на котором воспринимают данные пользователи,, называется внешним уровнем (external level), тогда как СУБД и операционная система воспринимают данные на внутреннем уровне (internal level). Именно на внутреннем уровне данные реально сохраняются с использованием всех тех структур и файловой организации, которые описаны в приложении Б, "Структура данных в файлах с различной организацией". Концептуальный уровень (conceptual level) представления данных предназначен для отображения внешнего уровня на внутренний и обеспечения необходимой независимости друг от друга.
2.1.1. Внешний уровень
Внешний Представление базы данных с точки зрения пользователей. Этот уро-уровень вень описывает ту часть базы данных, которая относится к каждому пользователю.
Внешний уровень состоит из нескольких различных внешних представлений базы данных. Каждый пользователь имеет дело с представлением "реального мира", выраженным в наиболее удобной для него форме. Внешнее представление содержит только те сущности, атрибуты и связи "реального мира", которые интересны пользователю. Другие сущности, атрибуты или связи, которые ему неинтересны, также могут быть представлены в базе данных, но пользователь может даже не подозревать об их существовании.
Помимо этого, различные представления могут по-разному отображать одни и те же данные. Например, один пользователь может просматривать даты в формате (день, месяц, год), а другой — в формате (год, месяц, день). Некоторые представления могут включать производные или вычисляемые данные, которые не хранятся в базе данных как таковые, а создаются по мере надобности. Например, в проекте DreamHome можно было бы организовать просмотр данных о возрасте сотрудников. Однако вряд ли стоит хранить эти сведения в базе данных, поскольку в таком случае их пришлось бы ежедневно обновлять. Вместо этого в базе данных хранятся даты рождения сотрудников, а возраст вычисляется средствами СУБД по обнаружении соответствующей ссылки. Представления могут также включать комбинированные или производные данные из нескольких объектов. Более подробно представления рассматриваются в разделах 3.5 и 14.1.
2.1.2. Концептуальный уровень
Концептуальный
Обобщающее представление базы данных. Этот уровень опи-
уровень сывает то, какие данные хранятся в базе данных, а также
связи, существующие между ними.
Промежуточным уровнем в трехуровневой архитектуре является концептуальный уровень. Этот уровень содержит логическую структуру всей базы данных (с точки зрения АБД). Фактически, это полное представление требований к данным со стороны организации, которое не зависит от любых соображений относительно способа их хранения. На концептуальном уровне представлены следующие компоненты:
• все сущности, их атрибуты и связи;
• накладываемые на данные ограничения;
• семантическая информация о данных;
• информация о мерах
обеспечения безопасности и поддержки целостности
данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных. Например, описание сущности должно содержать сведения о типах данных атрибутов (целочисленный, действительный или символьный) и их длине (количестве значащих цифр или максимальном количестве символов), но не должно включать сведений об организации хранения данных, например об объеме занятого пространства в байтах.
2.1.3. Внутренний уровень
Внутренний Физическое представление базы данных в компьютере. Этот уровень уровень описывает, как информация хранится в базе данных.
Внутренний уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в запоминающих устройствах. На этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы (вспомогательными функциями хранения и извлечения записей данных) с целью размещения данных на запоминающих устройствах, создания индексов, извлечения данных и т.д. На внутреннем уровне хранится следующая информация:
• распределение дискового пространства для хранения данных и индексов;
• описание подробностей
сохранения записей (с указанием реальных разме
ров сохраняемых элементов данных);
• сведения о размещении записей;
• сведения о сжатии данных и выбранных методах их шифрования.
Ниже внутреннего уровня находится физический уровень (physical level), который контролируется операционной системой, но под руководством СУБД. Однако функции СУБД и операционной системы на физическом уровне не вполне четко разделены и могут варьироваться от системы к системе. В одних СУБД используются многие предусмотренные в данной операционной системе методы доступа, тогда как в других применяются только самые основные и реализована собственная файловая организация. Физический уровень доступа к данным ниже СУБД состоит только из известных операционной системе элементов (например, указателей, как реализовано последовательное распределение и хранятся ли поля внутренних записей на диске в виде непрерывной последовательности байтов).
2.1.4. Схемы, отображения и экземпляры
Общее описание базы данных называется схемой базы данных. Существует три различных типа схем базы данных, которые определяются в соответствии с уровнями абстракции трехуровневой архитектуры, как показано на рис. 2.1. На самом высоком уровне имеется несколько внешних схем или подсхем, которые соответствуют разным представлениям данных. На концептуальном уровне описание базы данных называют концептуальной схемой, а на самом низком уровне абстракции — внутренней схемой.
Концептуальная схема описывает все элементы данных и связи между ними, с указанием необходимых ограничений поддержки целостности данных. Для каждой базы данных имеется только одна концептуальная схема. На нижнем уровне находится внутренняя схема, которая является полным описанием внутренней модели данных.
Она содержит определения хранимых записей, методы представления, описания полей данных, сведения об индексах и выбранных схемах хеширования. Для каждой базы данных существует только одна внутренняя схема.
СУБД отвечает за установление соответствия между этими тремя типами схем, а также за проверку их непротиворечивости. Иначе говоря, СУБД должна убедиться в том, что каждую внешнюю схему можно вывести на основе концептуальной схемы. Для установления соответствия между любыми внешней и внутренней схемами СУБД должна использовать информацию из концептуальной схемы. Концептуальная схема связана с внутренней схемой посредством концептуально внутреннего отображения. Оно позволяет СУБД найти фактическую запись или набор записей на физическом устройстве хранения, которые образуют логическую запись в
концептуальной схеме, с учетом любых ограничений, установленных для выполняемых над данной логической записью операций. Оно также позволяет обнаружить любые различия в именах объектов, именах атрибутов, порядке следования атрибутов, их типах данных и т.д. Наконец, каждая внешняя схема связана с концептуальной схемой с помощью, внешне концептуального отображения. С его помощью СУБД может отображать имена пользовательского представления на соответствующую часть концептуальной схемы.
Примеры различных уровней приведены на рис. 2.2. На нем показаны два различных внешних представления информации о персонале: одно состоит из личного номера сотрудника (Sno), его имени (FName) и фамилии (LName), возраста (Age), суммы зарплаты за год (Salary) и номера отделения компании, в котором этот сотрудник работает (Впо). Другое представление включает личный номер сотрудника (Staff_No), фамилию (LName) и номер отделения компании, в котором он работает (Впо). Эти внешние представления сливаются воедино в одном концептуальном представлении. Особенностью данного процесса слияния является то, что поле возраста сотрудника (Age) преобразуется в поле даты его рождения (DOB). СУБД поддерживает внешне концептуальное отображение. Например, поле Sno из первого внешнего представления отображается на поле Staff No в записи концептуального представления. Затем концептуальный уровень отображается на внутренний уровень, который содержит физическое описание структуры записи концептуального представления. На этом уровне определение структуры формулируется на языке высокого уровня. Эта структура содержит указатель (Next), который позволяет физически связать все записи о сотрудниках в единую цепочку. Обратите внимание, что порядок полей на внутреннем уровне отличается от порядка атрибутов, принятого на концептуальном уровне. Таков механизм, с помощью которого СУБД осуществляет концептуально внутреннее отображение.
Рис. 2.2. Различия между тремя уровнями представления данных
Важно различать описание базы данных и саму базу данных. Описанием базы данных является схема базы данных. Схема создается в процессе проектирования базы данных, причем предполагается, что она изменяется достаточно редко. Однако содержащаяся в базе данных информация может меняться часто — например, всякий раз при вставке сведений о новом сотруднике или новом объекте сдаваемой в аренду недвижимости. Совокупность информации, хранящейся в базе данных в любой определенный момент времени, называется состоянием базы данных. Следовательно, одной и той же схеме базы данных может соответствовать множество ее различных состояний. Схема базы данных иногда называется содержанием базы данных, а ее состояние — детализацией.
2.1.5. Независимость отданных
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных, которая означает, что изменения на нижних уровнях никак не влияют на верхние уровни. Различают два типа независимости от данных: логическую и физическую.
Логическая Логическая независимость от данных означает полную защищен-независимость ность внешних схем от изменений, вносимых в концептуальную отданных схему.
Такие изменения концептуальной схемы, как добавление или удаление новых сущностей, атрибутов или связей, должны осуществляться без необходимости внесения изменений в уже существующие внешние схемы или переписывания прикладных программ. Ясно, что пользователи, для которых эти изменения предназначались, должны знать о них, но очень важно, чтобы другие пользователи даже не подозревали об этом.
Физическая Физическая независимость от данных означает защищенность независимость концептуальной схемы от изменений, вносимых во внутреннюю от данных схему.
Такие изменения внутренней схемы, как использование различных файловых систем или структур хранения, разных устройств хранения, модификация индексов или хеширование, должны осуществляться без необходимости внесения изменений в концептуальную или внешнюю схемы. Пользователем могут быть замечены изменения только в общей производительности системы. На самом деле наиболее распространенной причиной внесения изменений во внутреннюю схему является именно недостаточная производительность выполнения операций. На рис. 2.3 показано место перечисленных выше типов независимости от данных в трехуровневой архитектуре СУБД.
Принятое в архитектуре ANSI-SPARC двухэтапное отображение может сказываться на эффективности работы, но при этом оно обеспечивает более высокую независимость от данных. Для повышения эффективности в модели ANSI-SPARC допускается использование прямого отображения внешних схем на внутренние, без обращения к концептуальной схеме. Однако это снижает уровень независимости от данных, поскольку при каждом изменении внутренней схемы потребуется внесение определенных изменений во внешнюю схему и все зависящие от нее прикладные программы.

Рис. 2.3. Реализация независимости от данных в трехуровневой архитектуре ANSI-SPARC
2.2. Языки баз данных
Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных (Data Definition Language — DDL) и языка управления данными (Data Manipulation Language — DML). Язык DDL используется для определения схемы базы данных, а язык DML — для чтения и обновления данных, хранимых в базе. Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках программирования высокого уровня, как COBOL, Fortran, Pascal, Ada или С. В этом случае язык высокого уровня принято называть базовым языком (host language). Перед компиляцией файла программы на базовом языке, содержащей внедренные операторы подъязыка данных, потребуется предварительно удалить эти операторы, заменив их вызовами соответствующих функций СУБД. Затем этот предварительно обработанный файл обычным образом компилируется с помещением результатов в объектный модуль, который компонуется с библиотекой, содержащей вызываемые в программе функции СУБД. После этого полученный программный текст будет готов к выполнению. Помимо механизма внедрения, для большинства подъязыков данных также предоставляются средства интерактивного выполнения их операторов, вводимых пользователем непосредственно со своего терминала.
2.2.1. Язык определения данных - DDL
Язык DDL Описательный язык, который позволяет АБД или пользователю описать и поименовать сущности, необходимые для работы некоторого приложения, а также связи, имеющиеся между различными сущностями.
Схема базы данных состоит из набора определений, выраженных на специальном языке определения данных — DDL. Язык DDL используется как для определения новой схемы, так и для модификации уже существующей. Этот язык нельзя использовать для управления данными.
Результатом компиляции DDL-операторов является набор таблиц, хранимый в особых файлах, называемых системным каталогом. В системном каталоге интегрированы метаданные — т.е. данные, которые описывают объекты базы данных, а также позволяют упростить способ доступа к ним и управления ими. Метаданные включают определения записей, элементов данных, а также другие объекты, представляющие интерес для пользователей или необходимые для работы СУБД. Перед доступом к реальным данным СУБД обычно обращается к системному каталогу. Для обозначения системного каталога также используются термины словарь данных и каталог данных, хотя первый из них (словарь данных) обычно относится к программному обеспечению более общего типа, чем просто каталог СУБД. Системные каталоги более подробно обсуждаются дальше, в разделе 2.7.
Теоретически для каждой схемы в трехуровневой архитектуре можно было бы выделить несколько различных языков DDL, а именно язык DDL внешних схем, язык DDL концептуальной схемы и язык DDL внутренней схемы. Однако на практике существует один общий язык DDL, который позволяет задавать спецификации, как минимум, для внешней и концептуальной схем.
2.2.2. Язык управления данными - DML
Язык DML Язык, содержащий набор операторов для поддержки основных операций манипулирования содержащимися в базе данными.
К операциям управления данными относятся:
• вставка ъ базу данных новых сведений;
• модификация сведений, хранимых в базе данных;
• извлечение сведений, содержащихся в базе данных;
• удаление сведений из базы данных.
Таким образом, одна из основных функций СУБД заключается в поддержке языка манипулирования данными, с помощью которого пользователь может создавать выражения для выполнения перечисленных выше операций с данными. Понятие манипулирования данными применимо как к внешнему и концептуальному уровням, так и к внутреннему уровню. Однако на внутреннем уровне для этого необходимо определить очень сложные процедуры низкого уровня, позволяющие выполнять доступ к данным весьма эффективно. На более высоких уровнях, наоборот, акцент переносится в сторону большей простоты использования и основные усилия направляются на обеспечение эффективного взаимодействия пользователя с системой.
Языки DML отличаются базовыми конструкциями извлечения данных. Следует различать два типа языков DML: процедурный и непроцедурный. Основное отличие между ними заключается в том, что процедурные языки указывают то, как можно получить результат оператора языка DML, тогда как непроцедурные языки описывают то, какой результат будет получен. Как правило, в процедурных языках записи рассматриваются по отдельности, тогда как непроцедурные языки оперируют с целыми наборами записей.
Процедурные языки DML
Процедурный
Язык, который позволяет сообщить системе о том, какие дан-
язык DML ные необходимы, и
точно указать, как их можно извлечь.
С помощью процедурного языка DML пользователь, а точнее — программист, указывает на то, какие данные ему необходимы и как их можно получить. Это значит, что пользователь должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой процедурный язык DML позволяет извлечь запись, обработать ее и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Языки DML сетевых и иерархических СУБД обычно являются процедурными (раздел 2.3).
Непроцедурные языки DML
Непроцедурный
Язык, который позволяет указать лишь то, какие данные тре-
язык DML буются, но не то, как
их следует извлекать.
Непроцедурные языки DML позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. С помощью непроцедурных языков DML пользователь указывает, какие данные ему нужны, без определения способа их получения. СУБД транслирует выражение на языке DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей. Данный подход освобождает пользователя от необходимости знать детали внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. В результате работа пользователя получает определенную степень независимости от данных. Непроцедурные языки часто также называют декларативными языками. Реляционные СУБД в той или иной форме обычно включают поддержку непроцедурных языков манипулирования данными — чаще всего это бывает язык структурированных запросов SQL (Structured Query Language) или язык запросов по образцу QBE (Query-by-Example). Непроцедурные языки обычно проще понять и использовать, чем процедурные языки DML, поскольку пользователем выполняется меньшая часть работы, а СУБД — большая. Более подробно язык SQL рассматривается в главах 13, "Язык SQL", и 14, "Дополнительные средства языка SQL", а язык QBE — в главе 15, "Язык QBE".
Часть непроцедурного языка DML, которая отвечает за извлечение данных, называется языком запросов. Язык запросов можно определить как высокоуровневый узкоспециализированный язык, предназначенный для удовлетворения различных требований по выборке информации из базы данных. В этом смысле термин "запрос" зарезервирован для обозначения оператора извлечения данных, выраженного с помощью языка запросов. Термины "язык запросов" и "язык управления данными" часто используются как синонимы, хотя, с технической точки зрения, это некорректно.
2.2.3. Языки 4GL
Аббревиатура "4GL" представляет собой сокращенный английский вариант написания термина язык четвертого поколения (Fourth-Generation Language). He существует четкого определения этого понятия, хотя, по сути, речь идет о некотором стенографическом варианте языка программирования. Если для организации некоторой операции с данными на языке третьего поколения (3GL) типа COBOL потребуется написать сотни строк кода, то для реализации этой же операции на языке четвертого поколения будет достаточно 10-20 строк.
В то время как языки третьего поколения являются процедурными, языки 4GL выступают как непроцедурные, поскольку пользователь определяет, что должно быть сделано, но не говорит, как именно желаемый результат должен быть достигнут. Предполагается, что реализация языков четвертого поколения будет в значительной мере основана на использовании компонентов высокого уровня, которые часто называют "инструментами четвертого поколения". Пользователю не потребуется определять все этапы выполнения программы, необходимые для решения поставленной задачи, а достаточно будет лишь определить нужные параметры, на основании которых упомянутые выше инструменты автоматически осуществят генерацию прикладного приложения. Ожидается, что языки четвертого поколения позволят повысить производительность работы на порядок, но за счет ограничения типов задач, которые можно будет решать с их помощью. Выделяют следующие типы языков четвертого поколения:
• языки представления
информации, например языки запросов или генера
торы
отчетов;
• специализированные
языки, например языки электронных таблиц и
баз
данных;
• генераторы приложений,
которые при создании приложений обеспечи
вают
определение, вставку, обновление или извлечение сведений из ба
зы
данных;
• языки очень высокого
уровня, предназначенные для генерации кода
приложений.
В качестве примеров языков четвертого поколения можно указать упоминавшиеся выше языки SQL и QBE. Рассмотрим вкратце некоторые другие типы 4ОЬ-языков.
Генераторы форм
Генератор форм представляет собой интерактивный инструмент, предназначенный для быстрого создания шаблонов ввода и отображения данных в экранных формах. Генератор форм позволяет пользователю определить внешний вид экранной формы, ее содержимое и место расположения на экране. С его помощью можно задавать цвета элементов экрана, а также другие характеристики, например полужирное, подчеркнутое, мерцающее или реверсивное начертание и т.д. Более совершенные генераторы форм позволяют создавать вычисляемые атрибуты с использованием арифметических операторов или обобщающих функций, а также задавать правила проверки вводимых данных.
Генераторы отчетов
Генератор отчетов является инструментом создания отчетов на основе хранимой в базе данных информации. Он подобен языку запросов в том смысле, что пользователю предоставляются средства создания запросов к базе данных и извлечения из нее информации, используемой для представления в отчете. Однако генераторы отчетов, как правило, предусматривают гораздо большие возможности управления внешним видом отчета. Генератор отчета позволяет либо автоматически определять вид получаемых результатов, либо с помощью специальных команд создавать свой собственный вариант внешнего вида печатаемого документа.
Существует два основных типа генераторов отчетов: языковой и визуальный. В первом случае для определения нужных для отчета данных и внешнего вида документа следует ввести соответствующую команду на некотором подъязыке. Во втором случае для этих целей используется визуальный инструмент, подобный генератору форм.
Генераторы графического представления данных
Этот генератор представляет собой инструмент, предназначенный для извлечения информации из базы данных и отображения ее в виде диаграмм с графическим представлением существующих тенденций и связей. Обычно с помощью подобного генератора создаются гистограммы, круговые, линейчатые, точечные диаграммы и т.д.
Генераторы приложений
Генератор приложений представляет собой инструмент для создания программ, взаимодействующих с базой данных. Применяя генератор приложений, можно сократить время, необходимое для проектирования полного объема требуемого прикладного программного обеспечения. Генераторы приложений обычно состоят из предварительно созданных модулей, содержащих фундаментальные функции, которые требуются для работы большинства программ. Эти модули, обычно создаваемые на языках высокого уровня, образуют "библиотеку" доступных функций. Пользователь указывает, какие задачи программа должна выполнить, а генератор приложений определяет, как их следует выполнить.
2.3. Модели данных и концептуальное моделирование
Выше уже упоминалось, что схема создается с помощью некоторого языка определения данных. На самом деле она создается на основе языка определения данных конкретной целевой СУБД. К сожалению, это язык относительно низкого уровня; с его помощью трудно описать требования к данным в масштабе всей организации так, чтобы созданная схема была доступна пониманию пользователей самых разных категорий. В чем мы действительно нуждаемся, так это в описании схемы на некотором, более высоком уровне, которое будем называть моделью данных.
Модель Интегрированный набор понятий для описания данных, связей между данных ними и ограничений, накладываемых на данные в некоторой организации.
Модель является представлением "реального мира" объектов и событий, а также существующих между ними связей. Это некоторая абстракция, в которой акцент делается на самых важных и неотъемлемых аспектах деятельности организации, а все второстепенные свойства игнорируются. Таким образом, можно сказать, что модель данных представляет саму организацию. Модель должна отражать основные концепции, представленные в таком виде, который позволит проектировщикам и пользователям базы данных обмениваться конкретными и недвусмысленными мнениями об их понимании роли тех или иных данных в этой организации. Модель данных можно рассматривать как сочетание трех указанных ниже компонентов.
• Структурная часть,
т.е. набор правил, по которым может быть построена
база
данных.
• Управляющая часть,
определяющая типы допустимых операций с данны
ми (сюда
относятся операции обновления и извлечения данных, а также
операции
изменения структуры базы данных).
• Набор ограничений
поддержки целостности данных (необязательно), га
рантирующих
корректность используемых данных.
Цель построения модели данных заключается в представлении данных в понятном виде. Если такое представление возможно, то модель данных можно будет легко применить при проектировании базы данных. Для отображения обсуждавшейся в разделе 2.1 архитектуры ANSI-SPARC можно идентифицировать следующие три связанные модели данных:
• внешнюю модель
данных, отображающую представления каждого сущест
вующего в
организации типа пользователей, которую иногда называют
предметной областью (Universe of Discourse — UoD);
• концептуальную модель
данных, отображающую логическое (или обоб
щенное)
представление о данных, не зависимое от типа выбранной СУБД;
• внутреннюю модель
данных, отображающую концептуальную схему опре
деленным
образом, понятным выбранной целевой СУБД.
В литературе предложено и опубликовано достаточно много моделей данных. Они подразделяются на три категории: объектные (object-based) модели данных, модели данных на основе записей (record-based) и физические модели данных. Первые две используются для описания данных на концептуальном и внешнем уровнях, а последняя — на внутреннем уровне.
2.3.1. Объектные модели данных
При построении объектных моделей данных используются такие понятия как сущности, атрибуты и связи. Сущность — это отдельный элемент (сотрудник, место или вещь, понятие или событие) организации, который должен быть представлен в базе данных. Атрибут — это свойство, которое описывает некоторый аспект объекта и значение которого следует зафиксировать, а связь является ассоциативным отношением между сущностями. Ниже перечислены некоторые наиболее общие типы объектных моделей данных.
• Модель типа "сущность-связь", или ER-модель (Entity-Relationship model).
• Семантическая модель.
• Функциональная модель.
• Объектно-ориентированная модель.
В настоящее время ER-модель стала одним из основных методов концептуального проектирования баз данных, и именно она положена в основу предлагаемой в этой книге методологии проектирования баз данных. Объектно-ориентированная модель расширяет определение сущности с целью включения в него не только атрибутов, которые описывают состояние объекта, но и действий, которые с ним связаны, т.е. его поведение. В таком случае говорят, что объект инкапсулирует состояние и поведение. Более подробно модель типа "сущность-связь" рассматривается в главе 5, "Модель "сущность-связь"", а объектно-ориентированная модель — в главах 21-23.
2.3.2. Модели данных на основе записей
В модели на основе записей база данных состоит из нескольких записей фиксированного формата, которые могут иметь разные типы. Каждый тип записи определяет фиксированное количество полей, каждое из которых имеет фиксированную длину. Существует три основных типа логических моделей данных на основе записей: реляционная модель данных (relational data model), сетевая модель данных (network data model) и иерархическая модель данных (hierarchical data model). Иерархическая и сетевая модели данных были созданы почти на десять лет раньше реляционной модели данных, а потому их связь с концепциями традиционной обработки файлов более очевидна.