Тема 1. DNS и DHCP - серверы.
Отображение физических адресов на IP-адреса: протоколы ARP и RARP
В протоколе IP-адрес узла, то есть адрес компьютера или порта маршрутизатора, назначается произвольно администратором сети и прямо не связан с его локальным адресом, как это сделано, например, в протоколе IPX (Novell Net Ware). Подход, используемый в IP, удобно использовать в крупных сетях и по причине его независимости от формата локального адреса, и по причине стабильности, так как в противном случае, при смене на компьютере сетевого адаптера это изменение должны бы были учитывать все адресаты всемирной сети Internet (в том случае, конечно, если сеть подключена к Internet'у).
Отображение символьных адресов на IP-адреса: служба DNS
DNS (Domain Name System) - это распределенная база данных, поддерживающая иерархическую систему имен для идентификации узлов в сети Internet. Служба DNS предназначена для автоматического поиска IP-адреса по известному символьному имени узла. Спецификация DNS определяется стандартами RFC 1034 и 1035. DNS требует статической конфигурации своих таблиц, отображающих имена компьютеров в IP-адрес.
Протокол DNS является служебным протоколом прикладного уровня. Этот протокол несимметричен - в нем определены DNS-серверы и DNS-клиенты. DNS-серверы хранят часть распределенной базы данных о соответствии символьных имен и IP-адресов. Эта база данных распределена по административным доменам сети Internet. Клиенты сервера DNS знают IP-адрес сервера DNS своего административного домена и по протоколу IP передают запрос, в котором сообщают известное символьное имя и просят вернуть соответствующий ему IP-адрес.
Если данные о запрошенном соответствии хранятся в базе данного DNS-сервера, то он сразу посылает ответ клиенту, если же нет - то он посылает запрос DNS-серверу другого домена, который может сам обработать запрос, либо передать его другому DNS-серверу. Все DNS-серверы соединены иерархически, в соответствии с иерархией доменов сети Internet. Клиент опрашивает эти серверы имен, пока не найдет нужные отображения. Этот процесс ускоряется из-за того, что серверы имен постоянно кэшируют информацию, предоставляемую по запросам. Клиентские компьютеры могут использовать в своей работе IP-адреса нескольких DNS-серверов, для повышения надежности своей работы.
База данных DNS имеет структуру дерева, называемого доменным пространством имен, в котором каждый домен (узел дерева) имеет имя и может содержать поддомены. Имя домена идентифицирует его положение в этой базе данных по отношению к родительскому домену, причем точки в имени отделяют части, соответствующие узлам домена.
Корень базы данных DNS управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Имена этих доменов должны следовать международному стандарту ISO 3166. Для обозначения стран используются трехбуквенные и двухбуквенные аббревиатуры, а для различных типов организаций используются следующие аббревиатуры:
§ com - коммерческие организации (например, microsoft.com);
§ edu - образовательные (например, mit.edu);
§ gov - правительственные организации (например, nsf.gov);
§ org - некоммерческие организации (например, fidonet.org);
§ net - организации, поддерживающие сети (например, nsf.net).
Каждый домен DNS администрируется отдельной организацией, которая обычно разбивает свой домен на поддомены и передает функции администрирования этих поддоменов другим организациям. Каждый домен имеет уникальное имя, а каждый из поддоменов имеет уникальное имя внутри своего домена. Имя домена может содержать до 63 символов. Каждый хост в сети Internet однозначно определяется своим полным доменным именем (fully qualified domain name, FQDN), которое включает имена всех доменов по направлению от хоста к корню. Пример полного DNS-имени:
citint.dol.ru.
Автоматизация процесса назначения IP-адресов узлам сети - протокол DHCP
Как уже было сказано, IP-адреса могут назначаться администратором сети вручную. Это представляет для администратора утомительную процедуру. Ситуация усложняется еще тем, что многие пользователи не обладают достаточными знаниями для того, чтобы конфигурировать свои компьютеры для работы в интерсети и должны поэтому полагаться на администраторов.
Протокол Dynamic Host Configuration Protocol (DHCP) был разработан для того, чтобы освободить администратора от этих проблем. Основным назначением DHCP является динамическое назначение IP-адресов. Однако, кроме динамического, DHCP может поддерживать и более простые способы ручного и автоматического статического назначения адресов.
В ручной процедуре назначения адресов активное участие принимает администратор, который предоставляет DHCP-серверу информацию о соответствии IP-адресов физическим адресам или другим идентификаторам клиентов. Эти адреса сообщаются клиентам в ответ на их запросы к DHCP-серверу.
При автоматическом статическом способе DHCP-сервер присваивает IP-адрес (и, возможно, другие параметры конфигурации клиента) из пула наличных IP-адресов без вмешательства оператора. Границы пула назначаемых адресов задает администратор при конфигурировании DHCP-сервера. Между идентификатором клиента и его IP-адресом по-прежнему, как и при ручном назначении, существует постоянное соответствие. Оно устанавливается в момент первичного назначения сервером DHCP IP-адреса клиенту. При всех последующих запросах сервер возвращает тот же самый IP-адрес.
При динамическом распределении адресов DHCP-сервер выдает адрес клиенту на ограниченное время, что дает возможность впоследствии повторно использовать IP-адреса другими компьютерами. Динамическое разделение адресов позволяет строить IP-сеть, количество узлов в которой намного превышает количество имеющихся в распоряжении администратора IP-адресов.
DHCP обеспечивает надежный и простой способ конфигурации сети TCP/IP, гарантируя отсутствие конфликтов адресов за счет централизованного управления их распределением. Администратор управляет процессом назначения адресов с помощью параметра "продолжительности аренды" (lease duration), которая определяет, как долго компьютер может использовать назначенный IP-адрес, перед тем как снова запросить его от сервера DHCP в аренду.
Примером работы протокола DHCP может служить ситуация, когда компьютер, являющийся клиентом DHCP, удаляется из подсети. При этом назначенный ему IP-адрес автоматически освобождается. Когда компьютер подключается к другой подсети, то ему автоматически назначается новый адрес. Ни пользователь, ни сетевой администратор не вмешиваются в этот процесс. Это свойство очень важно для мобильных пользователей.
Протокол DHCP использует модель клиент-сервер. Во время старта системы компьютер-клиент DHCP, находящийся в состоянии "инициализация", посылает сообщение discover (исследовать), которое широковещательно распространяется по локальной сети и передается всем DHCP-серверам частной интерсети. Каждый DHCP-сервер, получивший это сообщение, отвечает на него сообщением offer (предложение), которое содержит IP-адрес и конфигурационную информацию.
Компьютер-клиент DHCP переходит в состояние "выбор" и собирает конфигурационные предложения от DHCP-серверов. Затем он выбирает одно из этих предложений, переходит в состояние "запрос" и отправляет сообщение request (запрос) тому DHCP-серверу, чье предложение было выбрано.
Выбранный DHCP-сервер посылает сообщение DHCP-acknowledgment (подтверждение), содержащее тот же IP-адрес, который уже был послан ранее на стадии исследования, а также параметр аренды для этого адреса. Кроме того, DHCP-сервер посылает параметры сетевой конфигурации. После того, как клиент получит это подтверждение, он переходит в состояние "связь", находясь в котором он может принимать участие в работе сети TCP/IP. Компьютеры-клиенты, которые имеют локальные диски, сохраняют полученный адрес для использования при последующих стартах системы. При приближении момента истечения срока аренды адреса компьютер пытается обновить параметры аренды у DHCP-сервера, а если этот IP-адрес не может быть выделен снова, то ему возвращается другой IP-адрес.
В протоколе DHCP описывается несколько типов сообщений, которые используются для обнаружения и выбора DHCP-серверов, для запросов информации о конфигурации, для продления и досрочного прекращения лицензии на IP-адрес. Все эти операции направлены на то, чтобы освободить администратора сети от утомительных рутинных операций по конфигурированию сети.
Однако использование DHCP несет в себе и некоторые проблемы. Во-первых, это проблема согласования информационной адресной базы в службах DHCP и DNS. Как известно, DNS служит для преобразования символьных имен в IP-адреса. Если IP-адреса будут динамически изменятся сервером DHCP, то эти изменения необходимо также динамически вносить в базу данных сервера DNS. Хотя протокол динамического взаимодействия между службами DNS и DHCP уже реализован некоторыми фирмами (так называемая служба Dynamic DNS), стандарт на него пока не принят.
Во-вторых, нестабильность IP-адресов усложняет процесс управления сетью. Системы управления, основанные на протоколе SNMP, разработаны с расчетом на статичность IP-адресов. Аналогичные проблемы возникают и при конфигурировании фильтров маршрутизаторов, которые оперируют с IP-адресами.
Наконец, централизация процедуры назначения адресов снижает надежность системы: при отказе DHCP-сервера все его клиенты оказываются не в состоянии получить IP-адрес и другую информацию о конфигурации. Последствия такого отказа могут быть уменьшены путем использовании в сети нескольких серверов DHCP, каждый из которых имеет свой пул IP-адресов.
Тема 2. Развитие стека TCP/IP: протокол IPv.6
Технология стека TCP/IP сложилась в основном в конце 1970-х годов и с тех пор основные принципы работы базовых протоколов, таких как IP, TCP, UDP и ICMP, практически не изменились. Однако сам компьютерный мир за эти годы значительно изменился, поэтому долго назревавшие усовершенствования в технологии стека TCP/IP сейчас стали необходимостью.
Основными обстоятельствами, из-за которых требуется модификация базовых протоколов стека TCP/IP, являются следующие:
· Повышение производительности компьютеров и коммуникационного оборудования. За время существования стека производительность компьютеров возросла на два порядка, объемы оперативной памяти выросли более чем в 30 раз, пропускная способность магистрали Internet в Соединенных Штатах выросла в 800 раз.
· Появление новых приложений. Коммерческий бум вокруг Internet и использование ее технологий при создании intranet привели к появлению в сетях TCP/IP, ранее использовавшихся в основном в научных целях, большого количества приложений нового типа, работающих с мультимедийной информацией. Эти приложения чувствительны к задержкам передачи пакетов, так как такие задержки приводят к искажению передаваемых в реальном времени речевых сообщений и видеоизображений. Особенностью мультимедийных приложений является также передача очень больших объемов информации. Некоторые технологии вычислительных сетей, например, frame relay и ATM, уже имеют в своем арсенале механизмы для резервирования полосы пропускания для определенных приложений. Однако эти технологии еще не скоро вытеснят традиционные технологии локальных сетей, не поддерживающие мультимедийные приложения (например, Ethernet). Следовательно, необходимо компенсировать такой недостаток средствами сетевого уровня, то есть средствами протокола IP.
· Бурное расширение сети Internet. В начале 90-х годов сеть Internet расширялась очень быстро, новый узел появлялся в ней каждые 30 секунд, но 95-й год стал переломным - перспективы коммерческого использования Internet стали отчетливыми и сделали ее развитие просто бурным. Первым следствием такого развития стало почти полное истощение адресного пространства Internet, определяемого полем адреса IP в четыре байта.
· Новые стратегии администрирования. Расширение Internet связано с его проникновением в новые страны и новые отрасли промышленности. При этом в сети появляются новые органы администрирования, которые начинают использовать новые методы администрирования. Эти методы требуют появления новых средств в базовых протоколах стека TCP/IP.
Сообщество Internet уже несколько лет работает над разработкой новой спецификации для базового протокола стека - протокола IP. Выработано уже достаточно много предложений, от простых, предусматривающих только расширение адресного пространства IP, до очень сложных, приводящих к существенному увеличению стоимости реализации IP в высокопроизводительных (и так же недешевых) маршрутизаторах.
Основным предложением по модернизации протокола IP является предложение, разработанное группой IETF. Сейчас принято называть ее предложение версией 6 - IPv6, а все остальные предложения группируются под названием IP Next Generation, IPng.
В предложении IETF протокол IPv6 оставляет основные принципы IPv4 неизменными. К ним относятся дейтаграммный метод работы, фрагментация пакетов, разрешение отправителю задавать максимальное число хопов для своих пакетов. Однако в деталях реализации протокола IPv6 имеются существенные отличия от IPv4. Эти отличия коротко можно описать следующим образом.
- Использование более длинных адресов. Новый размер адреса - наиболее заметное отличие IPv6 от IPv4. Версия 6 использует 128-битные адреса (16 байт).
· Гибкий формат заголовка. Вместо заголовка с фиксированными полями фиксированного размера (за исключением поля Резерв), IPv6 использует базовый заголовок фиксированного формата плюс набор необязательных заголовков различного формата. Дополнительные заголовки дают возможность передать информацию, обеспечивающую безопасность, приоритетность и т.п.
· Поддержка резервирования пропускной способности. В IPv6 механизм резервирования пропускной способности заменяет механизм классов сервиса версии IPv4.
· Поддержка расширяемости протокола. Это одно из наиболее значительных изменений в подходе к построению протокола - от полностью детализированного описания протокола к протоколу, который разрешает поддержку дополнительных функций.
Адресация в IPv6
Адреса назначения и источника в IPv6 имеют длину 128 бит или 16 байт. Версия 6 обобщает специальные типы адресов версии 4 в следующих типах адресов:
· Unicast - индивидуальный адрес. Определяет отдельный узел - компьютер или порт маршрутизатора. Пакет должен быть доставлен узлу по кратчайшему маршруту.
· Cluster - адрес кластера. Обозначает группу узлов, которые имеют общий адресный префикс (например, присоединенных к одной физической сети). Пакет должен быть маршрутизирован группе узлов по кратчайшему пути, а затем доставлен только одному из членов группы (например, ближайшему узлу).
· Multicast - адрес набора узлов, возможно в различных физических сетях. Копии пакета должны быть доставлены каждому узлу набора, используя аппаратные возможности групповой или широковещательной доставки, если это возможно.
Как и в версии IPv4, адреса в версии IPv6 делятся на классы, в зависимости от значения нескольких старших бит адреса.
Большая часть классов зарезервирована для будущего применения. Наиболее интересным для практического использования является класс, предназначенный для провайдеров услуг Internet, названный Provider-Assigned Unicast.
Адрес этого класса имеет следующую структуру:
|
010 |
Идентификатор |
Идентификатор |
Идентификатор |
Идентификатор |
Каждому провайдеру услуг Internet назначается уникальный идентификатор, которым помечаются все поддерживаемые им сети. Далее провайдер назначает своим абонентам уникальные идентификаторы, и использует оба идентификатора при назначении блока адресов абонента. Абонент сам назначает уникальные идентификаторы своим подсетям и узлам этих сетей.
Абонент может использовать технику подсетей, применяемую в версии IPv4, для дальнейшего деления поля идентификатора подсети на более мелкие поля.
Описанная схема приближает схему адресации IPv6 к схемам, используемым в территориальных сетях, таких как телефонные сети или сети Х.25. Иерархия адресных полей позволит магистральным маршрутизаторам работать только со старшими частями адреса, оставляя обработку менее значимых полей маршрутизаторам абонентов.
Под поле идентификатора узла требуется выделения не менее 6 байт, для того чтобы можно было использовать в IP-адресах МАС-адреса локальных сетей непосредственно.
Для обеспечения совместимости со схемой адресации версии IPv4, в версии IPv6 имеется класс адресов, имеющих 0000 0000 в старших битах адреса. Младшие 4 байта адреса этого класса должны содержать адрес IPv4. Маршрутизаторы, поддерживающие обе версии адресов, должны обеспечивать трансляцию при передаче пакета из сети, поддерживающей адресацию IPv4, в сеть, поддерживающую адресацию IPv6, и наоборот.
Тема 3. Топологии сетей. Базовые сетевые технологии. Ethernet.
Типы сетей
Существует большой выбор сетей. Сети различаются по многим признакам:
· По скорости передачи
· По типу используемого кабеля
· По физическому расположению кабеля
· По формату пакетов (кадров)
Для классификации сетей часто используется два термина: архитектура и топология. Архитектура сети (network architecture) описывает конкретный стандарт сети – например, Ethernet, Token Ring или ARCnet. Основные типы сетей имеют подтипы – например, Ethernet 10BaseT или Token Ring 10 Мбит/с. Топология (topology) относится к физическому расположению кабеля сети.
Топологии сетей.
Существует три основные топологии: звезда, кольцо или шина. Иногда эти топологии комбинируются для получения гибридной или ячеистой сети.
Шинная топология.
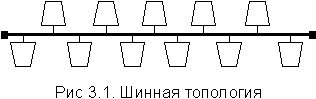 Шинная топология (bus topology) – самая простая и наиболее
часто используемая рис. 3.1. При этом каждый узел подключается к отрезку
кабеля, который соединяет все станции последовательно. Концы кабеля не
соединяются друг с другом, а заканчиваются каким-либо образом.
Шинная топология (bus topology) – самая простая и наиболее
часто используемая рис. 3.1. При этом каждый узел подключается к отрезку
кабеля, который соединяет все станции последовательно. Концы кабеля не
соединяются друг с другом, а заканчиваются каким-либо образом.
Недостаток такой сети состоит в том, что обрыв кабеля в каком-то месте выводит из строя всю сеть. Хотя шину очень легко проложить, необходимо тщательно спланировать расположение узлов, поскольку после прокладки шины не будет возможности перемещать рабочие станции.
 Кольцевая топология.
Кольцевая топология.
В кольцевой топологии (ring topology) каждый узел подключается к общему кабелю, концы которого соединены друг с другом в виде кольца рис. 3.2. Архитектуры, основанные на этой топологии (как Token Ring или FDDI), устойчивы к отказам связи с отдельными узлами; для выхода из строя всей сети должен произойти обрыв кольцевого кабеля.
Топология звезды.
В топологии звезды (star topology) каждый узел соединен с центром – соединительным модулем (hub) или концентратором (concentrator); он действует как центральный узел связи всей сети рис. 3.3. Некоторые модели соединительных модулей и концентраторов имеют встроенные диагностические средства, управляемые соответствующим программным обеспечением.
 Преимущество такой топологии заключается в
том, что при обрыве связи между одним из узлов и центром оставшаяся часть
продолжает работать. Только отказ соединительного модуля или концентратора
воздействует более чем на одну станцию.
Преимущество такой топологии заключается в
том, что при обрыве связи между одним из узлов и центром оставшаяся часть
продолжает работать. Только отказ соединительного модуля или концентратора
воздействует более чем на одну станцию.
Гибридная топология.
Гибридная топология – это комбинация нескольких различных топологий.
Гибридная топология популярна в глобальных сетях и сетях предприятий, в которых имеется основное – “становое” – кольцо, к которому подключаются остальные сети.
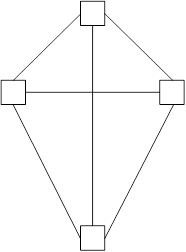
Ячеистая топология.
Наиболее отказоустойчивая топология сети – ячеистая (mesh topology). Каждый узел сети соединяется со всеми остальными рис. 3.4. Основное преимущество такой сети – она продолжает работать при отказе отдельного узла или разрыве любого кабеля. При обрыве кабельной секции данные могут быть перенаправлены через другие узлы и все равно достигнут места назначения.
К сожалению, такие сети чрезвычайно дороги и сложны в монтаже. Обычно эта топология используется в больших сетях, таких как Frame Relay или ATM, когда стоимость отступает на задний план перед производительностью и надежностью.
 Архитектуры сетей.
Архитектуры сетей.
Спросите любого администратора о том, какую сеть он использует, и его ответ наверняка будет начинаться со слов Ethernet, Token Ring или названия какой-то другой архитектуры. Архитектура сети определяет скорость передачи, стоимость и тип кабеля для сети.
В начале этого раздела описаны три сформировавшиеся архитектуры: Ethernet, Token Ring и ARCnet. Затем рассмотрены более новые и высокопроизводительные системы – FDDI, ATM и Ethernet со скоростью 100 Мбит/с. Сравнение различных архитектур сетей приведено в таблице.
|
Тип сети |
Скорость передачи, Мбит/с |
Типы кабелей |
Топологии |
|
Ethernet |
10 |
Coax, UTP |
Звезда, шина |
|
Token Ring |
4 или 16 |
UTP, STP |
Звезда, кольцо |
|
ARCnet |
2,5 |
Coax, UTP |
Звезда, шина |
|
FDDI |
100 |
Fiber optic |
Звезда, кольцо |
|
CDDI |
100 |
UTP, STP |
Звезда, кольцо |
|
ATM |
155 – 622 |
UTP, STP, fiber optic |
Звезда |
|
100VG-AnyLAN |
100 |
UTP, STP |
Звезда |
|
100BaseX |
100 |
UTP |
Звезда |
Ethernet.
Это, вероятно, самый старый тип сетей – он был изобретен Xerox Corporation в 1973 г. Несмотря на возраст, эта архитектура наиболее часто используется в сетях, так как обладает удачным сочетанием низкой стоимости и высокой производительности.
Ethernet – идеал для небольших и средних сетей. Его основные преимущества:
· Недорогие карты адаптеров. Сетевые карты (NIC) для Ethernet гораздо доступнее, чем карты для других сетей, таких как Token Ring или FDDI.
· Простота установки. В Ethernet можно использовать различные типы кабелей, и установка сети проста и дешева. В ряде случаев можно использовать существующий телефонный кабель.
· Широкое использование. Так как Ethernet используется повсеместно, продукцию для нее выпускают многие фирмы, и они могут помочь в оптимизации сети и повышении ее производительности. Другое преимущество – простота стыковки.
· Скорость. В зависимости от загрузки сети скорость передачи Ethernet в достигает 10 Мбит/с.
Однако при выборе Ethernet необходимо иметь в виду следующие ее недостатки:
· Плохая производительность при сильной загрузке. Используемый в Ethernet протокол обмена данными CSMA/CD плохо ведет себя при увеличении нагрузки на сеть. В больших сетях производительность Ethernet сильно падает с ростом потока сообщений в сети.
· Сложность диагностики. Версии Ethernet, основанные на шинной топологии, могут очень плохо поддаваться диагностике отказов. В шинной топологии отказ в одной точке приводит к остановке всей сети.
Протокол CSMA/CD Ethernet. Каждая сетевая архитектура должна иметь метод управления доступом нескольких устройств к одному кабелю. В Ethernet для регулирования доступа нескольких устройств к одному сетевому кабелю используется метод под названием CSMA/CD (carrier sense multiple access with collision detection). Это название расшифровывается как “множественный доступ с обнаружением несущей и разрешением столкновений”.
При работе Ethernet с CSMA/CD узел должен прослушать сетевой кабель перед тем, как пытаться передать что-либо по сети. Если узел не обнаружил в кабеле носителя сигнала, он передает кадр (носителем (carrier) называется электронный сигнал, свидетельствующий о том, что кабель занят другим устройством). Если кабель занят, перед повторной попыткой передачи узел должен определенное время подождать.
Когда адаптер начинает передачу, сигнал не достигает всех частей сети одновременно. На самом деле он передается по кабелю со скоростью, составляющей примерно 80% от скорости света.
После передачи кадра узел продолжает прослушивать кабель для обнаружения возможных столкновений (collisions). Если при занятом кабеле другой узел сети начинает передавать кадр, происходит столкновение. При этом кадры повреждаются. Перед повторной передачей кадров вовлеченные в столкновение станции должны отключиться и выждать случайный промежуток времени.
Перед повтором передачи нужно соблюдать осторожность, иначе сеть может оказаться перегруженной адаптерами, впустую пытающимися передавать, причем каждая передача будет приводить к коллизии. Чтобы избежать таких ситуаций, Ethernet использует стратегию двоичной экспоненциальной задержки, при которой отправитель ждет случайное время после первой коллизии, в два раза дольше, если вторая попытка передать, также привела к коллизии, в четыре раза дольше, если третья попытка привела к коллизии, и так далее. Идея, лежащая в основе экспоненциальной задержки, заключается в том, что при коллизии возможно, что большое число станций будет пытаться передавать одновременно и может возникнуть большие помехи для трафика. При таких помехах существует большая вероятность того, что две станции выберут похожие времена задержки. Поэтому вероятность того, что возникнет новая коллизия, велика. С помощью удвоения случайного времени задержки стратегия экспоненциальной задержки быстро распределяет попытки повторной передачи станций на достаточно большой промежуток времени, что делает вероятность дальнейших коллизий крайне маленькой.
Хотя в каждом кадре присутствует адрес узла назначения, каждый узел должен проверять все проходящие мимо него кадры. Если кадр не предназначен данному узлу, он передается следующему.
Если узел получает пакет, адресованный ему, перед обработкой пакета он должен проверить целостность данных. При этом тщательно проверяются некоторые поля полученного пакета. Первое и самое главное – узел должен проверить, что пакет не слишком длинный. В сетях Ethernet пакеты длиной более 1518 байт считаются слишком длинными; они не могут быть обработаны. Затем проверяется циклический избыточный код (cyclical redundancy check - CRC). И, наконец, последняя проверка – не является ли пакет слишком коротким. Длина пакета не может быть меньше 64 байт. Если пакет прошел эти проверки, он передается сетевому драйверу для дальнейшей обработки.
Вопрос на будущее! Чем объясняются ограничения на размер пакета Ethernet?
С ростом размера сети растет число столкновений в ней и, как следствие, падает производительность. Однако остроту этой проблемы можно сгладить за счет правильного распределения нагрузки на сеть и разбиения ее на сегменты (подсети).
Адресация Ethernet'а
Интерфейс ЭВМ Ethernet поддерживает механизм адресации, который позволяет передавать на компьютер только нужные пакеты. Напомним, что каждый интерфейс получает копию каждого пакета - даже если они адресованы другим машинам. Это оборудование фильтрует пакеты, игнорируя те, которые адресованы другим машинам, и передает в компьютер те, которые адресованы ему. Механизм адресации и фильтрации требуется, чтобы предохранить компьютер от перегрузки приходящими данными.
Чтобы позволить компьютеру определить, какие пакеты назначены ему, каждому компьютеру, соединенному с Ethernet-ом, назначено 48-битовое число, называемое Ethernet-овским адресом (MAC). Производители оборудования для Ethernet приобретают блоки адресов Ethernet и последовательно назначают эти адреса производимым ими интерфейсам для Ethernet (Институт Инженеров по Электротехнике и Радиотехнике(IEEE) управляет адресным пространством Ethernet и назначает адреса по мере необходимости). Поэтому никакие два интерфейса не будут иметь одинаковый адрес Ethernet.
Обычно Ethernet-овский адрес фиксируется в оборудовании интерфейса компьютера. Так как адреса Ethernet принадлежат аппаратным устройствам, то они иногда называются аппаратными адресами или физическими адресами. Отметим следующее важное свойство физических адресов Ethernetа:
Физические адреса связаны с интерфейса Ethernetа; установка интерфейса на новую машину или замена неисправного интерфейса изменяет его физический адрес.
Зная, что физические адреса Ethernetа могут меняться, легко понять, почему более высокие уровни сетевого математического обеспечения согласованы с такими изменениями. 48-битовый адрес Ethernet не только определяет отдельный аппаратный интерфейс. Он может принадлежать одному из трех типов:
- физический адрес одного сетевого интерфейса;
- широковещательный сетевой адрес;
- групповой адрес.
По соглашению широковещательный адрес (все единицы) зарезервирован для одновременной посылки всем станциям. Групповые адреса обеспечивают ограниченную форму широковещания, при которой группа компьютеров в сети согласна отвечать на групповой адрес. Каждый компьютер в такой группе может получать сообщения одновременно с другими компьютерами этой группы, при этом остальные машины в сети ничего не получают.
Для согласования с широковещательной и групповой адресацией интерфейс Ethernet должен распознавать не только свой физический адрес. Интерфейс обычно принимает, по крайней мере, два вида передач: адресованные физическому адресу интерфейса и адресованные широковещательному адресу. Некоторые интерфейсы могут быть запрограммированы на распознавание групповых адресов или даже альтернативных физических адресов. Когда операционная система начинает работать, она инициализирует интерфейс Ethernetа, задавая ему набор адресов, который он должен распознавать. В дальнейшем интерфейс сканирует каждую передачу, передавая на компьютер только передачи, предназначенные одному из указанных адресов.
Формат кадра Ethernet'а
Ethernet можно представлять как соединение канального уровня между машинами. Поэтому имеет смысл рассматривать передаваемые данные как кадры (фреймы) (Термин фрейм (граница) ведет свое происхождение от передачи по последовательным линиям, в которых отправитель определял границы данных, добавляя специальные символы перед и после передаваемых данных). Кадры Ethernet имеют переменную длину в пределах от 64 октетов (октетом называется блок из 8 бит, чаще называемый байтом) до 1518 октетов (заголовок, данные, ЦКС). Как и во всех сетях с коммутацией пакетов, кадр должен содержать данные, идентифицирующие назначение кадра. Рисунок 7.6 показывает формат кадра Ethernetа, который содержит физический адрес отправителя, а также физический адрес получателя.
Помимо идентификации отправителя и получателя, каждый кадр, передаваемый по Ethernetу, содержит преамбулу, поле типа, поле данных и циклическую контрольную сумму (CRC) или ЦКС. Преамбула состоит из 64 битовой последовательности 1 и 0 и служит для облегчения синхронизации при приеме. 32-битовая ЦКС помогает интерфейсу обнаружить ошибки передачи: отправитель вычисляет ЦКС как функцию от данных, передаваемых в кадре, а получатель заново вычисляет ЦКС для того, чтобы быть уверенным в том, что пакет принят без ошибок.
Поле типа кадра содержит 16-битовое целое число, которое идентифицирует тип данных, передаваемых в кадре. С точки зрения Интернета поле типа кадра очень важно, так как это означает, что кадры Ethernet являются самоидентифицирующимися. Когда кадр приходит на данную машину, операционная система использует тип кадра, чтобы определить, какой программный модуль обработки протоколов должен обработать это кадр. Главные преимущества самоидентифицирующихся кадров заключаются в том, что они позволяют одновременно использовать несколько протоколов на одной машине и в том, что они позволяют нескольким протоколам смешиваться при работе в одной физической сети. Например, кто-то может иметь прикладную программу, использующую Интернетовские протоколы, а кто-то использовать локальный экспериментальный протокол. Операционная система будет определять, кому послать приходящие пакеты, основываясь на значении поля типа кадра. Мы увидим, что протоколы TCP/IP используют самоидентифицирующиеся кадры Ethernet для выделения себя среди других протоколов.
адрес адрес тип
преамбула получателя отправителя кадра данные ЦКС
---------------------------------------------------------------
| 64 бита | 48 бит | 48 бит |16 бит|368-12000 бит| 32 бита|
| 8 байт | 6 байт | 6 байт |2 байт|368-12000 бит| 4 байта|
---------------------------------------------------------------
Рисунок 7.6 Формат кадра (пакета) в том виде, в котором он передается по Ethernet. Размеры полей не соотносятся друг с другом.
Типы кадров Ethernet. Вы уже знаете, что кадр или пакет – это единица информации, которую сетевая карта посылает в кабельную систему сети. В каждой сетевой архитектуре используется один или несколько форматов кадров. В Ethernet используется несколько форматов, в том числе Ethernet II, Raw 802.3, IEEE 802.2 и 802.2 SNAP.
ARP, RARP – протоколы.
При включении узлы сети знают свой IP-адрес и локальный адрес, но не знают локальных адресов друг друга. Для того, чтобы сформировать кадр Ethernet требуется узнать локальный адрес получателя.
Для определения локального адреса по IP-адресу используется протокол разрешения адреса Address Resolution Protocol, ARP. Протокол ARP работает различным образом в зависимости от того, какой протокол канального уровня работает в данной сети - протокол локальной сети (Ethernet, Token Ring, FDDI) с возможностью широковещательного доступа одновременно ко всем узлам сети, или же протокол глобальной сети (X.25, frame relay), как правило, не поддерживающий широковещательный доступ.
Существует также протокол, решающий обратную задачу - нахождение IP-адреса по известному локальному адресу. Он называется реверсивный ARP - RARP (Reverse Address Resolution Protocol) и используется при старте бездисковых станций, не знающих в начальный момент своего IP-адреса, но знающих адрес своего сетевого адаптера.
В локальных сетях протокол ARP использует широковещательные кадры протокола канального уровня для поиска в сети узла с заданным IP-адресом.
Узел, которому нужно выполнить отображение IP-адреса на локальный адрес, формирует ARP запрос, вкладывает его в кадр протокола канального уровня, указывая в нем известный IP-адрес, и рассылает запрос широковещательно. Все узлы локальной сети получают ARP запрос и сравнивают указанный там IP-адрес с собственным. В случае их совпадения узел формирует ARP-ответ, в котором указывает свой IP-адрес и свой локальный адрес и отправляет его уже направленно, так как в ARP запросе отправитель указывает свой локальный адрес. ARP-запросы и ответы используют один и тот же формат пакета.
Так как локальные адреса могут в различных типах сетей иметь различную длину, то формат пакета протокола ARP зависит от типа сети. На рисунке 3.2 показан формат пакета протокола ARP для передачи по сети Ethernet.
0 8 16 31
|
Тип сети |
Тип протокола |
|
|
Длина локального адреса |
Длина сетевого адреса |
Операция |
|
Локальный адрес отправителя (байты 0 - 3) |
|
|
|
Локальный адрес отправителя (байты 4 - 5) |
IP-адрес отправителя (байты 0-1) |
|
|
IP-адрес отправителя (байты 2-3) |
Искомый локальный адрес (байты 0 - 1) |
|
|
Искомый локальный адрес (байты 2-5) |
|
|
|
Искомый IP-адрес (байты 0 - 3) |
|
|
Рис. 3.2. Формат пакета протокола ARP
В поле типа сети для сетей Ethernet указывается значение 1. Поле типа протокола позволяет использовать пакеты ARP не только для протокола IP, но и для других сетевых протоколов. Для IP значение этого поля равно 080016.
Длина локального адреса для протокола Ethernet равна 6 байтам, а длина IP-адреса - 4 байтам. В поле операции для ARP запросов указывается значение 1 для протокола ARP и 2 для протокола RARP.
Узел, отправляющий ARP-запрос, заполняет в пакете все поля, кроме поля искомого локального адреса (для RARP-запроса не указывается искомый IP-адрес). Значение этого поля заполняется узлом, опознавшим свой IP-адрес.
В глобальных сетях администратору сети чаще всего приходится вручную формировать ARP-таблицы, в которых он задает, например, соответствие IP-адреса адресу узла сети X.25, который имеет смысл локального адреса. В последнее время наметилась тенденция автоматизации работы протокола ARP и в глобальных сетях. Для этой цели среди всех маршрутизаторов, подключенных к какой-либо глобальной сети, выделяется специальный маршрутизатор, который ведет ARP-таблицу для всех остальных узлов и маршрутизаторов этой сети. При таком централизованном подходе для всех узлов и маршрутизаторов вручную нужно задать только IP-адрес и локальный адрес выделенного маршрутизатора. Затем каждый узел и маршрутизатор регистрирует свои адреса в выделенном маршрутизаторе, а при необходимости установления соответствия между IP-адресом и локальным адресом узел обращается к выделенному маршрутизатору с запросом и автоматически получает ответ без участия администратора.
Подсети
Адресное пространство сети internet может быть разделено на непересекающиеся подпространства - "подсети", с каждой из которых можно работать как с обычной сетью TCP/IP. Таким образом, единая IP-сеть организации может строиться как объединение подсетей. Как правило, подсеть соответствует одной физической сети, например, одной сети Ethernet.
Конечно, использование подсетей необязательно. Можно просто назначить для каждой физической сети свой сетевой номер, например, номер класса C. Однако такое решение имеет два недостатка. Первый, и менее существенный, заключается в пустой трате сетевых номеров. Более серьезный недостаток состоит в том, что если ваша организация имеет несколько сетевых номеров, то машины вне ее должны поддерживать записи о маршрутах доступа к каждой из этих IP-сетей. Таким образом, структура IP-сети организации становится видимой для всего мира. При каких-либо изменениях в IP-сети информация о них должна быть учтена в каждой из машин, поддерживающих маршруты доступа к данной IP-сети.
Подсети позволяют избежать этих недостатков. Ваша организация должна получить один сетевой номер, например, номер класса B. Стандарты TCP/IP определяют структуру IP-адресов. Для IP-адресов класса B первые два байта являются номером сети. Оставшаяся часть IP-адреса может использоваться как угодно. Например, вы можете решить, что третий байт будет определять номер подсети, а четвертый байт - номер узла в ней. Вы должны описать конфигурацию подсетей в файлах, определяющих маршрутизацию IP-пакетов. Это описание является локальным для вашей организации и не видно вне ее. Все машины вне вашей организации видят одну большую IP-сеть. Следовательно, они должны поддерживать только маршруты доступа к шлюзам, соединяющим вашу IP-сеть с остальным миром. Изменения, происходящие в IP-сети организации, не видны вне ее. Вы легко можете добавить новую подсеть, новый шлюз и т.п.
Как назначать номера сетей и подсетей. Маска подсети.
После того, как решено использовать подсети или множество IP-сетей, вы должны решить, как назначать им номера. Обычно это довольно просто. Каждой физической сети, например, Ethernet или Token Ring, назначается отдельный номер подсети или номер сети. В некоторых случаях имеет смысл назначать одной физической сети несколько подсетевых номеров. Например, предположим, что имеется сеть Ethernet, охватывающая три здания. Ясно, что при увеличении числа машин, подключенных к этой сети, придется ее разделить на несколько отдельных сетей Ethernet (Здесь играет роль фактор большой загруженности сети). Для того, чтобы избежать необходимости менять IP-адреса, когда это произойдет, можно заранее выделить для этой сети три подсетевых номера - по одному на здание. (Это полезно и в том случае, когда не планируется физическое деление сети. Просто такая адресация позволяет сразу определить, где находится та или иная машина.) Однако прежде, чем выделять три различных подсетевых номера одной физической сети, тщательно проверьте, что все ваши программы способны работать в такой среде.
Вы также должны выбрать "маску подсети". Она используется сетевым программным обеспечением для выделения номера подсети из IP-адресов. Биты IP-адреса, определяющие номер IP-сети, в маске подсети должны быть равны 1, а биты, определяющие номер узла, в маске подсети должны быть равны 0. Как уже отмечалось, стандарты TCP/IP определяют количество октетов, задающих номер сети.
Часто в IP-адресах класса B третий байт используется для задания номера подсети. Это позволяет иметь 256 подсетей, в каждой из которых может быть до 254 узлов. Маска подсети в такой системе равна 255.255.255.0. Но, если в вашей сети должно быть больше подсетей, а в каждой подсети не будет при этом более 60 узлов, то можно использовать маску 255.255.255.192 (11000000= 2**6+2**7=128+64).Это позволяет иметь 1024 подсети и до 62 узлов в каждой. (Напомним, что номера узлов 0 и "все единицы" используются особым образом.)
Если адрес Вашей сети принадлежит классу С, то можно использовать первые биты четвертого байта IP-адреса под номер подсети. Очевидно, что количество подсетей всегда равно степени двойки. Пусть нам достаточно выделить 3 подсети. Для номера подсети требуется выделить 2 бита. Следовательно, реально мы можем организовать четыре подсети.
Алгоритм назначения адреса подсети аналогичен алгоритму разбиения IP-адресов на классы.
|
4 байт адреса |
минимальный IP-адрес |
максимальный IP-адрес |
|
00000000 |
0 |
63 |
|
01000000 |
64 |
127 |
|
10000000 |
128 |
191 |
|
11000000 |
192 |
255 |
Итак, мы видим, что с учетом групповых, широковещательных и специальных IP-адресов в каждой подсети может быть не более 62 компьютеров. Маска этой сети выглядит так же, как и в предыдущем примере, т.е. 255.255.255.192.
Обычно маска подсети указывается в файле стартовой конфигурации сетевого программного обеспечения. Протоколы TCP/IP позволяют также запрашивать эту информацию по сети.
Тема 4. Базовые сетевые технологии. Token Ring.
Token Ring.
 Значительным вкладом IBM в сетевую индустрию является архитектура Token Ring.
Целью этой разработки являлась платформа, обеспечивающая надежную и
высокопроизводительную работу сетей, характеристики функционирования которых не
носили бы вероятностного характера, присущего Ethernet.
Хотя эта архитектура дороже, чем Ethernet, она обладает
более высокой производительностью, а диагностика отказов в ней гораздо легче,
особенно в сильно загруженной сети. (Существует два уровня производительности Token Ring 4
Мбит/с и 16 Мбит/с.)
Значительным вкладом IBM в сетевую индустрию является архитектура Token Ring.
Целью этой разработки являлась платформа, обеспечивающая надежную и
высокопроизводительную работу сетей, характеристики функционирования которых не
носили бы вероятностного характера, присущего Ethernet.
Хотя эта архитектура дороже, чем Ethernet, она обладает
более высокой производительностью, а диагностика отказов в ней гораздо легче,
особенно в сильно загруженной сети. (Существует два уровня производительности Token Ring 4
Мбит/с и 16 Мбит/с.)
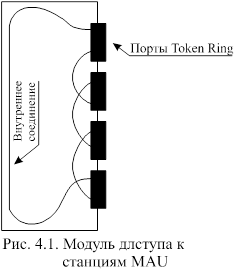
Электрически Token Ring работает как кольцо с передачей маркера (token-passing ring), физически же это конфигурация звезды. Для того чтобы понять работу этого кольца, заглянем внутрь его модуля доступа к станциям (multistation access unit - MAU). На рис. 4.1 можно видеть, что каждый порт MAU связан с остальными. После подключения станций к MAU формируется кольцо.
Передача данных по сети Token Ring происходит в строгом порядке. В сети от станции к станции циркулирует специальный 24-битовый пакет – так называемый маркер (token). Когда узел получает маркер, он имеет возможность послать в кольцо кадр данных. Перед тем как станция передаст маркер дальше, она присоединяет к кадру маркера информационный кадр. После этого маркер становится либо кадром управления доступом к передающей среде (medium access control - MAC), либо кадром управления логическим каналом передачи данных (logical link control - LLC). Эта информация включает также адрес (или адреса) получателя пересылаемой информации. Этот кадр проходит по всему кольцу и в конце концов возвращается в пославший его узел. По завершении передачи станция-источник выполняет очистку кадра маркера, удаляя любую дополнительную информацию, привязанную к пакету, и возвращает маркер в кольцо, следующей станции. И затем вся процедура повторяется вновь.
Встроенное управление сетью Token Ring. Высокая стоимость и сложность сетей Token Ring оправдывается их высокой устойчивостью к отказам. Хотя кольцо и может отказать, встроенные средства Token Ring очень сильно уменьшают вероятность полного отказа. В каждом сетевом адаптере запрограммирован набор управляющих функций, описанных стандартом 802.5. При этом узел играет активную роль в управлении всей сетью, работая как монитор.
Основной монитор кольца называется активным монитором (active monitor - AM). При инициализации кольца проверяется адрес каждого подключенного узла. Узел с наивысшем адресом становится активным монитором. После его назначения активный монитор отвечает за работу сети.
Во-первых, активный монитор должен убедиться, что маркер правильно циркулирует по кольцу. Для этого, как только узел назначен активным монитором, он инициализирует очистку кольца и выдает новый маркер. При потере или повреждении маркера активный монитор отвечает за выдачу нового. Многочисленные таймеры следят за событиями в кольце и определяют, когда АМ следует сгенерировать новый маркер. Один из них, называемый T (ANY_TOKEN), указывает, прошел ли маркер через АМ в течении определенного промежутка времени.
Для поддержки активного монитора все остальные узлы сети называются резервными мониторами (standby monitor). Их назначение – проверять, правильно ли работает активный монитор. При отключении активного монитора один из резервных мониторов становится активным.
Роль управляющих станций очень важна для поддержания целостности связи в кольце. Управляющие станции обеспечивают функции управления локальным кольцом и функции сервера, связанные с управлением кольцом.
В процессе управления кольцом управляющая станция может выполнять следующие функции:
· пассивного монитора (standby monitor – SM);
· активного монитора (active monitor – AM);
· сервера отчетов о конфигурациях (configuration report server – CRS);
· сервера параметров кольца (ring parameter server – RPS);
· монитора ошибок кольца (ring error monitor – REM);
· сервера моста LAN (LAN bridge server – LBS);
· механизма выдачи отчетов LAN (LAN reporting mechanism – LRM).
Пассивные мониторы. Роль пассивных мониторов (SM) не ограничена управляющими функциями. Скорее всего они являются кольцевыми станциями (RS) общего назначения. Пассивные мониторы действительно время от времени обеспечивают функции локального управления, поскольку они отвечают за обнаружение сбоев, происходящих в активном мониторе. Если SM не обнаруживают в кольце МАС-кадра активного монитора, то они вступают в состязание за роль активного монитора (AM).
Важно отметить, что агент на сетевой плате каждой RS используется в МАС-взаимодействии с такими основными управляющими станциями, как АМ, CRS, RPS, REM, LBS и LRM.
SM обращается к управляющим станциям, когда им необходимо принять участие в “переговорах” по управлению кольцом. Сами управляющие станции также могут инициализировать подобные переговоры для получения доступа к определенной информации в SM о самой этой станции либо о текущем кадре, которым она управляет.
SM могут также запрашивать некоторые важные параметры кольца от одной из управляющих станций.
Активный монитор. Активный монитор (АМ) является главным менеджером связи в кольце. Он отвечает за поддержание передачи данных и управляющую информацию, циркулирующую между всеми станциями кольца.
АМ отвечает за выполнение следующих семи основных функций:
· поддержку главного тактового генератора;
· инициирование уведомления соседа;
· мониторинг уведомления соседа;
· поддержание надлежащей задержки в кольце;
· мониторинг передачи маркера и кадра;
· выявление утерянных маркеров и кадров;
· очистку кольца.
Поддержка главного тактового генератора.
АМ отвечает за поддержку главного тактового генератора кольца, который определяет временные соотношения в сети Token Ring, обеспечивая синхронизацию тактовых генераторов всех станций. Главный тактовый генератор обращается к таймерам протоколов Token Ring, являющимся неотъемлемой частью архитектуры Token Ring.
Инициирование уведомления соседа.
АМ регулярно передает МАС-кадр Active Monitor Present. Этот кадр передается не реже, чем каждые семь секунд одним из таймеров протоколов Token Ring, встроенных в архитектуру Token Ring, – T(Neighbor_Notification). АМ отвечает за циркуляцию передачи этого кадра на все станции кольца. Передача этого кадра инициирует процесс уведомления соседа (Neighbor Notification).
Мониторинг уведомления соседа.
АМ поддерживает постоянный процесс уведомления соседа. Для контроля этого процесса он использует таймеры протоколов Token Ring. Если во время этой операции происходят какие-то прерывания, то в целях стабилизации кольца АМ выполняет необходимые управляющие функции по средствам передачи МАС-кадра.
Поддержание надлежащей задержки в кольце.
АМ вводит в кольцо 24-битовый шаблон задержки. Это обеспечивает полную передачу станции-получателю маркера, посланного станцией-отправителем, до того, как этот маркер вернется на станцию-отправитель. Отсутствие такой 24-битовой задержки может привести к появлению в кольце различных накладок, выраженных в нарушении временных соотношений.
Мониторинг передачи маркера и кадра.
АМ опрашивает бит монитора в поле управления доступом каждого маркера и кадра, который он перехватывает. Этот бит монитора используется в качестве “резервной точки” для проверки завершения передачи кадра между станциями в кольце. АМ проверяет, не выполнен ли сброс этого бита последней передачей в кольце. Если статус оказывается неправильным, АМ выполняет очистку кольца.
Обнаружение утерянных маркеров и кадров.
Архитектура Token Ring ограничивает максимальное время оборота кадра в кольце 10 мс. Для проверки этого 10 мс интервала АМ обращается к таймеру протоколов Token Ring, называемому Т(Any_Token). АМ пытается обнаружить начальный ограничитель от кадра или маркера в рамках заданного таймером интервала. Если ему не удается обнаружить кадр, а заданный интервал уже истек, АМ выполняет очистку кольца.
Очистка кольца.
АМ обеспечивает широковещательную передачу кадра Ring Purge, когда необходимо очистить кольцо перед выдачей нового маркера. Это происходит в тех случаях, когда АМ выявляет в кольце нарушение синхронизации между работой станций или сбой в выполнении того или иного процесса Token Ring. Когда АМ вырабатывает этот кадр, он переключает все RS в режим Normal Repeat, а также реинициализирует все таймеры протоколов Token Ring. Это приводит к перезапуску процесса уведомления соседа (Neighbor Notification).
Только одна станция в кольце является активным монитором в каждый данный момент времени. Эта роль назначается динамически в соответствии с процессами Token Ring в данном кольце. АМ может быть назначена любая RS в кольце. Активная RS с текущим наивысшим активным адресом в кольце, захватывающая управление процессом Token Claiming, становится АМ.
Вниз по потоку и вверх против потока.
Двумя логическими направлениями перемещения по кольцу являются направления вверх против потока (upstream) и вниз по потоку (downstream). Направление перемещения данных по кольцу – всегда вниз по потоку.
Маркер всегда передается на следующую станцию в направлении вниз по потоку. Станция, которая передает маркер, называется ближайшим активным соседом, расположенным вверх против потока (nearest active upstream neighbor - NAUN), - по отношению к следующей активной станции вниз по потоку, которая принимает маркер.
NAUN.
Концепция NAUN очень важна в среде Token Ring, поскольку является непосредственной точкой отсчета для управления связью и адресации станций в кольце. Одна из наиболее важных задач NAUN заключается в функции уведомления соседа. Процесс уведомления соседа (Neighbor Notification process) позволяет кольцевой станции (ring station - RS) узнать адрес своего NAUN.
Другая важная функция NAUN заключается в локализации неисправности в кольце до уровня некоторой области, называемой доменом неисправности (fault domain). Когда в кольце происходит сбой, концепция NAUN позволяет локализовать проблему до уровня домена неисправности.
Уведомление соседа.
Уведомление соседа (Neighbor Notification) – это последовательный логический процесс, в ходе которого каждая RS узнает адрес своего NAUN.
Режим нормального повторения.
У каждой станции есть состояние, называемое режимом нормального повторения. Находясь в этом состоянии, RS опрашивает все принимаемые ею маркеры и кадры и может соответствующим образом копировать и повторять их.
Очистка кольца.
Процесс очистки кольца (ring purge) представляет собой попытку установки кольца в режим нормального повторения. АМ инициирует процесс очистки кольца в следующих случаях:
· при обнаружении в кольце ошибки;
· если в поле управления доступом маркера или кадра М-бит установлен в 1;
· если кольцо требуется перевести в режим нормального повторения;
· когда АМ обнаруживает, что интервал таймера Т(Any_Token) истек.
Сгенерировав кадр, АМ ожидает приема этого кадра обратно. Если кадр принят, АМ полагает, что кольцо стабилизировано, и сбрасывает все таймеры протоколов Token Ring, после чего инициирует процесс Neighbor Notification для перезапуска и перевода кольца обратно в режим нормального повторения.
В Token Ring используются две основные разновидности кабеля: экранированная витая пара (STP) и не экранированная витая пара (UTP). Для каждого кабеля существует свой разъем. Для экранированного кабеля используется разъем UDC (иначе называемый IBM Data Connector); для неэкранированного кабеля применяется разъем RJ45.
Хотя экранированный кабель дороже неэкранированного, он имеет значительные преимущества. Как уже говорилось экранированный кабель более стоек к электромагнитным помехам. Поэтому иногда просто необходимо использовать экранированный кабель, что гарантирует надежную работу сети. Другое обстоятельство, которое необходимо принять во внимание, – предполагаемый размер сети. Экранированный витой кабель может поддерживать большее число узлов, чем неэкранированный.
Token Ring 16 Мбит/с может работать с неэкранированным кабелем IBM тип 5 при использовании фильтра среды (media filter). Использование типа кабеля ниже пятого может привести к непредсказуемым последствиям.
Как и в Ethernet, необходимо иметь в виду ограничение по длине кабеля и максимальному количеству узлов. В таблице приведены спецификации того, что IBM называет малой переносимой сетью Token Ring (small movable Token Ring network), построенной с помощью IBM MAU и экранированного кабеля. Использую концентраторы, фильтры и лучший кабель, можно превзойти эти ограничения. Однако делать это нужно осторожно.
|
Ограничение |
Значение |
|
Максимальное число узлов |
96 |
|
Максимальное число MAU |
12 |
|
Максимальная длина кабеля при соединении двух MAU |
50 футов |
|
Максимальная длина кабеля, соединяющего все MAU |
400 футов |
|
Максимальное расстояние между MAU и узлом |
150 футов |
MAU – центральный узел всей сети. В зависимости от конфигурации он может иметь 4, 6, 8, 12 или 16 портов для подключения узлов и два специальных порта – Ring-In (RI) и Ring-Out (RO), предназначенные для соединения двух и более MAU в кольцо. Предположим, у вас есть 8-портовые модули MAU, и нужно создать сеть с 10 рабочими станциями. Для получения электрического кольца необходимо соединить два MAU с помощью портов RI и RO. Порт RI первого MAU соединяется кабелем с портом RO второго; другим кабелем порт RO первого MAU соединяется с портом RI второго рис. 4.2. Таким образом, создается электрическое кольцо между двумя MAU. Некоторые поставщики предлагают “разумные” MAU, которые не нуждаются во втором кабеле между портами RO и RI. MAU фирмы IBM или совместимые с ними необходимо инициализировать с помощью небольшого устройства. Это устройство вставляется в каждый порт и создает слабый электрический ток, который сбрасывает реле в портах MAU, при этом слышен щелчок.
Устройства сети Token Ring.
Кабели. Стандарт Token Ring определяет семь типов кабельных соединений, которые известны под общим названием кабельная система IBM. Все семь типов кабелей имеют индивидуальные конструктивные спецификации; их использование и прокладка осуществляется в соответствии с определенными рекомендациями, касающимися длины кабельных соединений. Например, кабель тип 3 – неэкранированная витая пара – максимальная длина абонентского кабеля 45 метров. Этот тип кабеля поддерживает до 72 узлов. Кабель типа 3 сопрягается со стандартным разъемом данных IBM через специальный переходник, оснащенный фильтром помех. Кабель типа 3 обычно использует для оконечной нагрузки стандартный телефонный разъем RJ11 или RJ45.
Устройства многостанционного доступа и концентраторы кабельных соединений. Современные модели концентраторов, предназначенных для работы в локальных сетях, включают встроенные развитые логические возможности. Концентраторы снабжены диагностическим программным обеспечением для тестирования концентратора независимо от сетевой операционной системы. Самые популярные новые серии концентраторов включают интеллектуальные устройства, поддерживающие кабель типа UTP. Системы кабельных соединений типа UTP сравнительно недороги и удобны в эксплуатации. В некоторых случаях они допускают большие расстояния, чем те, что предусмотрены соответствующими спецификациями. Некоторые из них рассчитаны на применение смешанных топологий, обеспечивая межсетевые связи.
 Мосты. Мост (bridge)
представляет собой устройство, которое соединяет одну локальную сеть с другой
на уровне линии передачи данных OSI.
Мосты. Мост (bridge)
представляет собой устройство, которое соединяет одну локальную сеть с другой
на уровне линии передачи данных OSI.
Некоторые мосты называются мостами MAC-уровня, поскольку осуществляют связь на уровне МАС. Связь этого вида возможна при условии однородности двух локальных сетей. Например, если локальная сеть Token Ring соединена мостом с другой сетью Token Ring, они могут полностью осуществлять связь через мост МАС-уровня. Но если локальная сеть Token Ring соединена мостом с локальной сетью Ethernet, то эти локальные сети считаются разнородными и не могут взаимодействовать на МАС-уровне. В этом случае используется мост LLC-уровня.
Маршрутизаторы. Маршрутизатор (router) отличается от моста тем, что соединяет одну локальную сеть с другой на сетевом уровне OSI, а не на уровне передачи данных. Маршрутизаторы используются при объединении локальных сетей, работа которых регламентируется одними и теми же протоколами. Чаще всего они действуют в больших объединенных сетях, где существует необходимость в логическом разделении локальных сетей.
Повторители. Повторитель работает на физическом уровне – самом нижнем уровне модели OSI. Эти устройства (repeater) электрически удлиняют физическую протяженность кабельного сегмента локальной сети. Они принимают сигнал из одного кабельного сегмента, усиливают его и передают его в другой кабельный сегмент.
Управление средой кольца.
Управление физическим уровнем Token Ring осуществляется по средствам ряда функций, присущих архитектуре Token Ring. Каждая станция в кольце имеет сетевую плату, которая содержит агента. Этот агент взаимодействует с определенными управляющими станциями Token Ring в кольце по средствам передачи кадров МАС. Роль управляющей станции заранее определена архитектурой Token Ring.
ARCnet.
В 1977 г. Datapoint Corporation выпустила собственную сетевую систему - ARCnet. Хотя это сеть могла быть организованна и как звезда рисунок 5.1, и как шина рисунок 5.2, электрически она представляет собой шину с передачей маркера (token-passing bus), работающую со скоростью 2,5 Мбит/с.
Основное преимущество ARCnet – гибкость. Стандартные системы ARCnet работают с коаксиальным кабелем RG62, но ARCnet в состоянии работать с неэкранированным витым кабелем и даже волоконной оптикой. При установке сети ARCnet в виде звезды имеются две возможности. В качестве центрального узла сети можно использовать активный или пассивный соединительный модуль.
К сожалению, ARCnet не завоевала успеха. Низкая скорость и отсутствие стандарта IEEE, а также снижение цен на Ethernet привели к сильному сокращению рынка сбыта ARCnet.
Скоростные сетевые архитектуры.
В настоящее время существуют или появляются различные высокоскоростные архитектуры сетей. В очень больших сетях, как правило, небольшие сети соединяются вместе, образуют межсетевое объединение (internetwork). Часто все эти сети подключаются к некоторой базовой сети (backbone network).Так как эта базовая сеть работает связующим звеном между многими сетями, ей требуется более высокая производительность, чем отдельным подсетям. Для обеспечения наивысшей производительности используются такие типы сетей, как FDDI и CDDI со скоростью 100 Мбит/с (FDDI – fiber optic distributed data interface – оптоволоконный интерфейс передачи данных; CDDI – copper distributed data interface – проводной интерфейс передачи данных), Ethernet 100 Мбит/с и АТМ (asynchronous transfer method – асинхронный метод передачи), обеспечивающий скорость передачи до 622 Мбит/с.
FDDI и CDDI.
Волоконнооптические сети FDDI предназначены для обеспечения широкой полосы пропускания с помощью волоконнооптического кабеля. Для этой архитектуры American National Standard Institute (ANSI) разработан стандарт Х3Т9.5. Хотя FDDI изначально был разработан для использования волоконной оптики, новейшие достижения позволили перенести эту высокоскоростную надежную архитектуру на неэкранированные и экранированные витые кабели; поэтому в названии сети слово fiber-optic – волоконная оптика – сменилось на copper – медь. Такая архитектура обозначается CDDI.
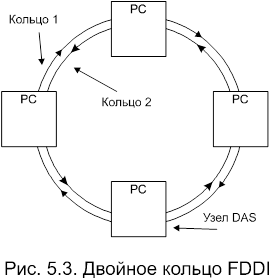 Сеть FDDI близка к
стандарту IEEE 802.5 кольца с передачей маркера, но с
некоторыми отличиями. В то время как стандарт 802.5 определяет наличие одного
кольца, соединяющего точку с точкой, простейшая сеть FDDI
использует два противоположно направленных кольца, соединяющих узлы. Эти два
кольца – первичное и вторичное – увеличивают отказоустойчивость системы по
сравнению со стандартом 802.5.
Сеть FDDI близка к
стандарту IEEE 802.5 кольца с передачей маркера, но с
некоторыми отличиями. В то время как стандарт 802.5 определяет наличие одного
кольца, соединяющего точку с точкой, простейшая сеть FDDI
использует два противоположно направленных кольца, соединяющих узлы. Эти два
кольца – первичное и вторичное – увеличивают отказоустойчивость системы по
сравнению со стандартом 802.5.
 В обычной кольцевой топологии отказ кольцевого
кабеля (который обычно находится внутри MAU или
концентратора), приводит к остановке всей сети. В FDDI,
при наличии дополнительного кольца, если в первичном кольце (которое передает
данные по часовой стрелке) происходит сбой, данные могут быть перенаправлены
через вторичное кольцо. Как видно из рисунка 5.3, если узел не может связаться
с соседним по кольцу, он может направить данные во второе кольцо, работающее в
направлении против часовой стрелки. Узлы в кольце FDDI
могут быть разделены на две категории. Первая (и самая общая) – станция с
двойным подключением (dual attachment station
- DAS). Узел DAS подключается
одновременно к обоим кольцам и может справиться со сбоем в одном из колец.
Второй тип узла – станция с одиночным подключением (single attachment station - SAS) – соединяется с
кольцом FDDI через концентратор или соединительный
модуль, подключенный к главному кольцу рисунок 5.4. Эти станции не могут
работать при сбое в кольце до тех пор, пока он не устранен.
В обычной кольцевой топологии отказ кольцевого
кабеля (который обычно находится внутри MAU или
концентратора), приводит к остановке всей сети. В FDDI,
при наличии дополнительного кольца, если в первичном кольце (которое передает
данные по часовой стрелке) происходит сбой, данные могут быть перенаправлены
через вторичное кольцо. Как видно из рисунка 5.3, если узел не может связаться
с соседним по кольцу, он может направить данные во второе кольцо, работающее в
направлении против часовой стрелки. Узлы в кольце FDDI
могут быть разделены на две категории. Первая (и самая общая) – станция с
двойным подключением (dual attachment station
- DAS). Узел DAS подключается
одновременно к обоим кольцам и может справиться со сбоем в одном из колец.
Второй тип узла – станция с одиночным подключением (single attachment station - SAS) – соединяется с
кольцом FDDI через концентратор или соединительный
модуль, подключенный к главному кольцу рисунок 5.4. Эти станции не могут
работать при сбое в кольце до тех пор, пока он не устранен.
Отказоустойчивость – не единственное преимущество FDDI. Стандарт FDDI устанавливает, что при использовании повторителей сеть может иметь длину до 200 км и содержать до 1000 узлов. Длина прямой связи между узлами может достигать 2 км.
Другое преимущество FDDI связано со способом передачи. В волоконнооптическом кабеле данные посылаются не с помощью электрического тока, а световыми импульсами. Поскольку свет не подвержен воздействию электромагнитных помех, FDDI удобно использовать на заводах и в других местах, где имеется много электрических машин.
Как и другие высокоскоростные сети, FDDI имеет один существенный недостаток – высокую цену.
АТМ.
АТМ (asynchronous transfer method – асинхронный метод передачи) был разработан в конце 1991 года.
АТМ – гибкая и мощная технология, ломающая многие барьеры, встающие при разработке современного оборудования. АТМ, именуемая также сетью с ретрансляцией ячеек (cell-relay network), обеспечивает высокоскоростную связь между отдельными пунктами. АТМ предназначена для оптимальной обработки и данных и голоса, в отличие от других сетей, которые предназначены либо для одного, либо для другого. В отличие от традиционных сетевых архитектур, передающих большие пакеты объемом в сотни и тысячи байт, АТМ при передаче оперирует очень маленькими блоками – ячейками (cells). Размер ячейки – 53 байта. Поскольку ячейки очень малы и допускают передачу по различным носителям, АТМ можно использовать и для локальных, и для глобальных сетей.
Также в отличие от других сетевых архитектур, в АТМ используется переключения ячеек (cell switches). Концентраторы АТМ в действительности представляют собой очень быстрые переключатели, которые устанавливают прямую логическую связь с устройством, с которым вы обмениваетесь информацией. На время передачи и приема информации вся пропускная способность сетевой коммуникационной системы предоставлена в ваше распоряжение. В других сетевых архитектурах пропускная способность коммуникационной системы все время делится более или менее равномерно между всеми подключенными устройствами. Переключение иногда используется в Ethernet для снятия ограничений, накладываемых протоколом CSMA/CD.
Одно из основных преимуществ архитектуры АТМ – гибкость. Так как АТМ не ограничивается глобальными сетями, в ее топологии имеется множество вариантов. Топология АТМ традиционно определяется как топология звезды, хотя во многих случаях более точно ее следует называть гибридной.
Ethernet 100 Мбит/с.
По мере усложнения сетей усложнялись и приложения, работающие в них. Мультимедиа, телеконференции, компьютерное проектирование (CAD) быстро поглощают пропускную способность сетей. Token Ring ответила на этот вызов выходом более скоростной версии – 16 Мбит/с. Однако Ethernet, первой завоевавшая рынок, до сих пор не предлагала повышения производительности. Ныне существуют два способа повышения скорости передачи Ethernet до 100 Мбит/с.
В конце 1993 года IEEE приступил к рассмотрению двух предложений архитектуры Ethernet, рассчитанных на скорость передачи 100 Мбит/с. В ответ на первое предложение был создан комитет 802.12 для изучения архитектуры 10VG-AnyLAN, предложенной Hewlett-Packard и IBM. Эта разработка основывалась на более ранней – 100Base-VG, предложенной Hewlett-Packard, AT&T и некоторыми другими организациями. Второй проект – 100BaseX (иначе Fast Ethernet) – был представлен Grand Junction Networks и рассматривался комитетом 802.3.
100VG-AnyLAN.
Эта архитектура рассчитана на скорость передачи 100 Мбит/с и в корне меняет структуру Ethernet. 100VG-AnyLAN – это сеть Ethernet без протокола CSMA/CD. Вместо него используется новый протокол под названием Demand Priority и способ сигнализации под названием Quartet Signaling.
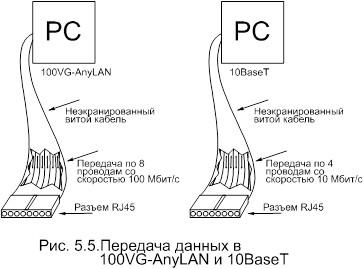 В отличие от обычной сети Ethernet,
где используется две пары проводов – одна для обнаружения носителей и другая
для передачи – в 100VG-AnyLAN
для одновременной передачи используется четыре пары проводов. Для этого
используется Quartet Signaling в сочетании с новой схемой кодирования сигнала 5В6В
NRZ, что позволяет за один цикл передать удвоенное количество
битов по каждой паре проводов. На рисунке 5.5 можно увидеть разницу между
передачей по стандартной сети Ethernet и по 100VG-AnyLAN. Хотя метод сигнализации в
100VG-AnyLAN может отличаться
от принятого в Ethernet, частоты передачи схожи, и
поэтому 100VG-AnyLAN
удовлетворяет требованиям FCC по ограничению излучений.
В отличие от обычной сети Ethernet,
где используется две пары проводов – одна для обнаружения носителей и другая
для передачи – в 100VG-AnyLAN
для одновременной передачи используется четыре пары проводов. Для этого
используется Quartet Signaling в сочетании с новой схемой кодирования сигнала 5В6В
NRZ, что позволяет за один цикл передать удвоенное количество
битов по каждой паре проводов. На рисунке 5.5 можно увидеть разницу между
передачей по стандартной сети Ethernet и по 100VG-AnyLAN. Хотя метод сигнализации в
100VG-AnyLAN может отличаться
от принятого в Ethernet, частоты передачи схожи, и
поэтому 100VG-AnyLAN
удовлетворяет требованиям FCC по ограничению излучений.
Протокол Demand Priority, пришедший на смену CAMA/CD, более эффективен и имеет значительные преимущества. С использованием протокола CSMA/CD сети (теоретически) работают со скоростью 10 Мбит/с. Однако при увеличении загрузки сети ее пропускная способность резко падает из-за увеличения числа столкновений пакетов (эти столкновения не возникают в протоколе Demand Priority). В отличии от CSMA/CD, где каждый узел сам определяет, послать ли ему данные и в какой момент это сделать, в сети с протоколом Demand Priority ответственность за порядок передачи ложится на соединительный модуль.
 Если узел сети 100VG-AnyLAN должен передать
данные, он сначала посылает соединительному модулю запрос на передачу. Если
сеть свободна, соединительный модуль подтверждает получение запроса и ожидает
перехода данных от узла. После получения данных от узла соединительный модуль
декодирует их, чтобы получить адрес узла назначения, а затем посылает данные
непосредственно этому узлу. На рисунке 5.6 показана передача данных между двумя
узлами в двух архитектурах – 10BaseT и 100VG-AnyLAN. В отличие от CSMA/CD, протокол Demand Priority гарантирует, что данные будут известны только двум
узлам – передающему и принимающему. Это обеспечивает дополнительный уровень
безопасности сети, минимизируя вероятность подслушивания.
Если узел сети 100VG-AnyLAN должен передать
данные, он сначала посылает соединительному модулю запрос на передачу. Если
сеть свободна, соединительный модуль подтверждает получение запроса и ожидает
перехода данных от узла. После получения данных от узла соединительный модуль
декодирует их, чтобы получить адрес узла назначения, а затем посылает данные
непосредственно этому узлу. На рисунке 5.6 показана передача данных между двумя
узлами в двух архитектурах – 10BaseT и 100VG-AnyLAN. В отличие от CSMA/CD, протокол Demand Priority гарантирует, что данные будут известны только двум
узлам – передающему и принимающему. Это обеспечивает дополнительный уровень
безопасности сети, минимизируя вероятность подслушивания.
Дополнительное преимущество 100VG-AnyLAN и протокола Demand Priority заключается в том, что при этом приложению обеспечивается структурированная система приоритетов (priority system). Большинство систем управления базами данных могут посылать данные в режиме нормального приоритета, но некоторым системам (например, телеконференция) для нормальной работы требуется повышенная пропускная способность. Эти системы могут посылать данные с более высоким уровнем приоритета. Соединительный модуль гарантирует, что такие запросы будут обслуживаться раньше остальных. За счет этого отдельным узлам и приложениям обеспечивается гарантированная пропускная способность.
В отношении кабельного соединения 100VG-AnyLAN также очень гибка. В соответствии с предложенной спецификацией, можно использовать неэкранированный витой кабель уровня 3 или 5, экранированный витой кабель IBM тип 1 или волоконнооптический кабель. При соединении новой сети необходимо использовать кабель уровня 5, но тем не менее замену существующей сети на 100VG-AnyLAN можно провести очень просто. Большинство современных сетей 10BaseT работают с кабелем уровня 3, так что при замене их на 100VG-AnyLAN можно сэкономить тысячи, если не десятки тысяч долларов за счет сохранения кабельной системы.
Но не смотря на свои явные преимущества, эта технология не поучила достаточного распространения.
100BaseX (Fast Ethernet).
Предложенная Grand Junction Networks, 3Com, Synoptics и некоторыми другими фирмами архитектура 100BaseX (известная также под названием Fast Ethernet) очень похожа на стандартную архитектуру Ethernet с протоколом CSMA/CD. Стандарт 100BaseX изучается комитетом 802.3 IEEE.
Имеются различные варианты кабельной системы сети. 100BaseX может работать с неэкранированным витым кабелем уровня 5, с экранированным витым кабелем IBM тип 1 или волоконнооптическим кабелем. Если в сети 10BaseT использовался неэкранированный кабель уровня 3, то для использования сети 100BaseX его необходимо заменить на кабель уровня 5. С другой стороны, в новых сетях необходимо использовать только уровень 5, специально предназначенный для передачи данных.